MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON. But it's faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves.
Next:
MessagePack is supported by over 50 programming languages and environments. See list of implementations.
Redis scripting has support for MessagePack because it is a fast and compact serialization format with a simple to implement specification. I liked it so much that I implemented a MessagePack C extension for Lua just to include it into Redis.
Salvatore Sanfilippo, creator of Redis
Fluentd uses MessagePack for all internal data representation. It's crazy fast because of zero-copy optimization of msgpack-ruby. Now MessagePack is an essential component of Fluentd to achieve high performance and flexibility at the same time.
Sadayuki Furuhashi, creator of Fluentd
Treasure Data built a multi-tenant database optimized for analytical queries using MessagePack. The schemaless database is growing by billions of records every month. We also use MessagePack as a glue between components. Actually we just wanted a fast replacement of JSON, and MessagePack is simply useful.
Kazuki Ohta, CTO
MessagePack has been simply invaluable to us. We use MessagePack + Memcache to cache many of our feeds on Pinterest. These feeds are compressed and very quick to unpack thanks to MessagePack while Memcache gives us fast atomic pushes.
MessagePack for Actionscript3 (Flash, Flex and AIR).
as3-msgpack was designed to work with the interfaces IDataInput and IDataOutput, thus the API might be easily connected with the native classes that handle binary data (such as ByteArray, Socket, FileStream and URLStream).
Moreover, as3-msgpack is capable of decoding data from binary streams.
Get started: http://loteixeira.github.io/lib/2013/08/19/as3-msgpack/
Basic usage (encoding/decoding):
// create messagepack objectvar msgpack:MsgPack =new MsgPack();// encode an arrayvarbytes:ByteArray= msgpack.write([1, 2, 3, 4, 5]);// rewind the bufferbytes.position=0;// print the decoded objecttrace(msgpack.read(bytes));
This library is only for serialize / deserialize.
To send / receive serialized data with Stream class, please use MsgPacketizer.
#include<MsgPack.h>// input to msgpackint i = 123;
float f = 1.23;
MsgPack::str_t s = "str"; // std::string or String
MsgPack::arr_t<int> v {1, 2, 3}; // std::vector or arx::vector
MsgPack::map_t<String, float> m {{"one", 1.1}, {"two", 2.2}, {"three", 3.3}}; // std::map or arx::map// output from msgpackint ri;
float rf;
MsgPack::str_t rs;
MsgPack::arr_t<int> rv;
MsgPack::map_t<String, float> rm;
voidsetup() {
delay(2000);
Serial.begin(115200);
Serial.println("msgpack test start");
// serialize to msgpack
MsgPack::Packer packer;
packer.serialize(i, f, s, v, m);
// deserialize from msgpack
MsgPack::Unpacker unpacker;
unpacker.feed(packer.data(), packer.size());
unpacker.deserialize(ri, rf, rs, rv, rm);
if (i != ri) Serial.println("failed: int");
if (f != rf) Serial.println("failed: float");
if (s != rs) Serial.println("failed: string");
if (v != rv) Serial.println("failed: vector<int>");
if (m != rm) Serial.println("failed: map<string, int>");
Serial.println("msgpack test success");
}
voidloop() {}
Encode / Decode to Collections without Container
In msgpack, there are two collection types: Array and Map.
C++ containers will be converted to one of them but you can do that from individual parameters.
To pack / unpack values as such collections in a simple way, please use these functions.
packer.to_array(i, f, s); // becoms array format [i, f, s];
unpacker.from_array(ii, ff, ss); // unpack from array format to ii, ff, ss
packer.to_map("i", i, "f", f); // becoms {"i":i, "f":f}
unpacker.from_map(ki, ii, kf, ff); // unpack from map to ii, ff, ss
The same conversion can be achieved using serialize and deserialize.
packer.serialize(MsgPack::arr_size_t(3), i, f, s); // [i, f, s]
unpacker.deserialize(MsgPack::arr_size_t(3), ii, ff, ss);
packer.serialize(MsgPack::map_size_t(2), "i", i, "f", f); // {"i":i, "f":f}
unpacker.deserialize(MsgPack::map_size_t(2), ki, ii, kf, ff);
Here, MsgPack::arr_size_t and MsgPack::map_size_t are used to identify the size of Array and Map format in serialize or deserialize.
This way is expandable to pack and unpack complex data structure because it can be nested.
// {"i":i, "arr":[ii, iii]}
packer.serialize(MsgPack::map_size_t(2), "i", i, "arr", MsgPack::arr_size_t(2), ii, iii);
unpacker.deserialize(MsgPack::map_size_t(2), ki, i, karr, MsgPack::arr_size_t(2), ii, iii);
Custom Class Adaptation
To serialize / deserialize custom type you defined, please use MSGPACK_DEFINE() macro inside of your class. This macro enables you to convert your custom class to Array format.
In other languages like JavaScript, Python and etc. has also library for msgpack.
But some libraries can NOT convert msgpack in "plain" style.
They always wrap them into collections like Array or Map by default.
For example, you can't convert "plain" format in other languages.
packer.serialize(i, f, s); // "plain" format is NOT unpackable
packer.serialize(arr_size_t(3), i, f, s); // unpackable if you wrap that into Array
It is because the msgpack is used as based on JSON (I think).
So you need to use Array format for JSON array, and Map for Json Object.
To achieve that, there are several ways.
use to_array or to_map to convert to simple structure
use serialize() or deserialize() with arr_size_t / map_size_t for complex structure
use custom class as JSON array / object which is wrapped into Array / Map
use custom class nest recursively for more complex structure
use ArduinoJson for more flexible handling of JSON
Use MsgPack with ArduinoJson
you can [serialize / deserialize] StaticJsonDocument<N> and DynamicJsonDocument directly
You can directly save/load to/from JSON file with this library. SD, SdFat, SD_MMC, SPIFFS, etc. are available for the target file system. Please see save_load_as_json_file example for more details.
#include<SD.h>
#include<MsgPack.h>structMyConfig {
Meta meta;
Data data;
MSGPACK_DEFINE(meta, data);
};
MyConfig config;
voidsetup() {
SD.begin();
// load json data from /config.txt to config struct directly
MsgPack::file::load_from_json_static<256>(SD, "/config.txt", config);
// change your configuration...// save config data from config struct to /config.txt as json directly
MsgPack::file::save_as_json_static<256>(SD, "/config.txt", config);
}
Save/Load to/from EEPROM with MsgPack
In Arduino, you can use the MsgPack utility to save/load to/from EEPROM. Following code shows how to use them. Please see save_load_eeprom example for more details.
structMyConfig {
Meta meta;
Data data;
MSGPACK_DEFINE(meta, data);
};
MyConfig config;
voidsetup() {
EEPROM.begin();
// load current configMsgPack::eeprom::load(config);
// change your configuration...// saveMsgPack::eeprom::save(config);
EEPROM.end();
}
Supported Type Adaptors
These are the lists of types which can be serialize and deserialize.
You can also pack() or unpack() variable one by one.
NIL
MsgPack::object::nil_t
Bool
bool
Integer
char (signed/unsigned)
ints (signed/unsigned)
Float
float
double
Str
char*
char[]
std::string or String(Arduino) (MsgPack::str_t)
Bin
unsigned char* (need to serialize(ptr, size) or pack(ptr, size))
unsigned char[] (need to serialize(ptr, size) or pack(ptr, size))
STL is used to handle packet data by default, but for following boards/architectures, ArxContainer is used to store the packet data because STL can not be used for such boards.
The storage size of such boards for max packet binary size and number of msgpack objects are limited.
AVR
megaAVR
SAMD
Memory Management (for NO-STL Boards)
As mentioned above, for such boards like Arduino Uno, the storage sizes are limited.
And of course you can manage them by defining following macros.
But these default values are optimized for such boards, please be careful not to excess your boards storage/memory.
// msgpack serialized binary size
#defineMSGPACK_MAX_PACKET_BYTE_SIZE128// max size of MsgPack::arr_t
#defineMSGPACK_MAX_ARRAY_SIZE8// max size of MsgPack::map_t
#defineMSGPACK_MAX_MAP_SIZE8// msgpack objects size in one packet
#defineMSGPACK_MAX_OBJECT_SIZE24
These macros have no effect for STL enabled boards.
In addtion for such boards, type aliases for following types are different from others.
MsgPack::str_t = String
MsgPack::bin_t<T> = arx::vector<T, N = MSGPACK_MAX_PACKET_BYTE_SIZE>
MsgPack::arr_t<T> = arx::vector<T, N = MSGPACK_MAX_ARRAY_SIZE>
MsgPack::map_t<T, U> = arx::map<T, U, N = MSGPACK_MAX_MAP_SIZE>
Please see "Memory Management" section and ArxContainer for detail.
STL library for Arduino Support
For such boards, there are several STL libraries, like ArduinoSTL, StandardCPlusPlus, and so on.
But such libraries are mainly based on uClibc++ and it has many lack of function.
I considered to support them but I won't support them unless uClibc++ becomes much better compatibility to standard C++ library.
I reccomend to use low cost but much better performance chip like ESP series.
This Arduino library provides a light weight serializer and parser for messagepack.
Install
Download the zip, and import it with your Arduino IDE: Sketch>Include Library>Add .zip library
Usage
See the either the .h file, or the examples (led_controller and test_uno_writer).
In short:
functions like msgpck_what_next(Stream * s); watch the next type of data without reading it (without advancing the buffer of Stream s).
functions like msgpck_read_bool(Stream * s, bool *b) read a value from Stream s.
functions like msgpck_write_bool(Stream * s, bool b) write a value on Stream s.
Notes:
Stream are used as much as possible in order not to add to much overhead with buffers. Therefore you should be able to store the minimum number of value at a given time.
Map and Array related functions concern only their headers. Ex: If you want to write an array containing two elements you should write the array header, then write the two elements.
Limitations
Currently the library does not support:
8 bytes float (Only 4 bytes floats are supported by default on every Arduino and floats are anyway not recommended on Arduino)
CMP is a C implementation of the MessagePack serialization format. It
currently implements version 5 of the MessagePack
Spec.
CMP's goal is to be lightweight and straightforward, forcing nothing on the
programmer.
License
While I'm a big believer in the GPL, I license CMP under the MIT license.
Example Usage
The following examples use a file as the backend, and are modeled after the
examples included with the msgpack-c project.
#include<stdio.h>
#include<stdlib.h>
#include"cmp.h"staticboolread_bytes(void *data, size_t sz, FILE *fh) {
returnfread(data, sizeof(uint8_t), sz, fh) == (sz * sizeof(uint8_t));
}
staticboolfile_reader(cmp_ctx_t *ctx, void *data, size_t limit) {
returnread_bytes(data, limit, (FILE *)ctx->buf);
}
staticboolfile_skipper(cmp_ctx_t *ctx, size_t count) {
returnfseek((FILE *)ctx->buf, count, SEEK_CUR);
}
staticsize_tfile_writer(cmp_ctx_t *ctx, constvoid *data, size_t count) {
returnfwrite(data, sizeof(uint8_t), count, (FILE *)ctx->buf);
}
staticvoiderror_and_exit(constchar *msg) {
fprintf(stderr, "%s\n\n", msg);
exit(EXIT_FAILURE);
}
intmain(void) {
FILE *fh = NULL;
cmp_ctx_t cmp = {0};
uint32_t array_size = 0;
uint32_t str_size = 0;
char hello[6] = {0};
char message_pack[12] = {0};
fh = fopen("cmp_data.dat", "w+b");
if (fh == NULL) {
error_and_exit("Error opening data.dat");
}
cmp_init(&cmp, fh, file_reader, file_skipper, file_writer);
if (!cmp_write_array(&cmp, 2)) {
error_and_exit(cmp_strerror(&cmp));
}
if (!cmp_write_str(&cmp, "Hello", 5)) {
error_and_exit(cmp_strerror(&cmp));
}
if (!cmp_write_str(&cmp, "MessagePack", 11)) {
error_and_exit(cmp_strerror(&cmp));
}
rewind(fh);
if (!cmp_read_array(&cmp, &array_size)) {
error_and_exit(cmp_strerror(&cmp));
}
/* You can read the str byte size and then read str bytes... */if (!cmp_read_str_size(&cmp, &str_size)) {
error_and_exit(cmp_strerror(&cmp));
}
if (str_size > (sizeof(hello) - 1)) {
error_and_exit("Packed 'hello' length too long\n");
}
if (!read_bytes(hello, str_size, fh)) {
error_and_exit(cmp_strerror(&cmp));
}
/* * ...or you can set the maximum number of bytes to read and do it all in * one call*/
str_size = sizeof(message_pack);
if (!cmp_read_str(&cmp, message_pack, &str_size)) {
error_and_exit(cmp_strerror(&cmp));
}
printf("Array Length: %u.\n", array_size);
printf("[\"%s\", \"%s\"]\n", hello, message_pack);
fclose(fh);
return EXIT_SUCCESS;
}
Advanced Usage
See the examples folder.
Fast, Lightweight, Flexible, and Robust
CMP uses no internal buffers; conversions, encoding and decoding are done on
the fly.
CMP's source and header file together are ~4k LOC.
CMP makes no heap allocations.
CMP uses standardized types rather than declaring its own, and it depends only
on stdbool.h, stdint.h and string.h.
CMP is written using C89 (ANSI C), aside, of course, from its use of
fixed-width integer types and bool.
On the other hand, CMP's test suite requires C99.
CMP only requires the programmer supply a read function, a write function, and
an optional skip function. In this way, the programmer can use CMP on memory,
files, sockets, etc.
CMP is portable. It uses fixed-width integer types, and checks the endianness
of the machine at runtime before swapping bytes (MessagePack is big-endian).
CMP provides a fairly comprehensive error reporting mechanism modeled after
errno and strerror.
CMP is thread aware; while contexts cannot be shared between threads, each
thread may use its own context freely.
CMP is tested using the MessagePack test suite as well as a large set of custom
test cases. Its small test program is compiled with clang using -Wall -Werror -Wextra ... along with several other flags, and generates no compilation
errors in either clang or GCC.
CMP's source is written as readably as possible, using explicit, descriptive
variable names and a consistent, clear style.
CMP's source is written to be as secure as possible. Its testing suite checks
for invalid values, and data is always treated as suspect before it passes
validation.
CMP's API is designed to be clear, convenient and unsurprising. Strings are
null-terminated, binary data is not, error codes are clear, and so on.
CMP provides optional backwards compatibility for use with other MessagePack
implementations that only implement version 4 of the spec.
Building
There is no build system for CMP. The programmer can drop cmp.c and cmp.h
in their source tree and modify as necessary. No special compiler settings are
required to build it, and it generates no compilation errors in either clang or
gcc.
Versioning
CMP's versions are single integers. I don't use semantic versioning because
I don't guarantee that any version is completely compatible with any other. In
general, semantic versioning provides a false sense of security. You should be
evaluating compatibility yourself, not relying on some stranger's versioning
convention.
Stability
I only guarantee stability for versions released on
the releases page. While rare, both master and develop
branches may have errors or mismatched versions.
Backwards Compatibility
Version 4 of the MessagePack spec has no BIN type, and provides no STR8
marker. In order to remain backwards compatible with version 4 of MessagePack,
do the following:
Avoid these functions:
cmp_write_bin
cmp_write_bin_marker
cmp_write_str8_marker
cmp_write_str8
cmp_write_bin8_marker
cmp_write_bin8
cmp_write_bin16_marker
cmp_write_bin16
cmp_write_bin32_marker
cmp_write_bin32
Use these functions in lieu of their v5 counterparts:
cmp_write_str_marker_v4 instead of cmp_write_str_marker
cmp_write_str_v4 instead of cmp_write_str
cmp_write_object_v4 instead of cmp_write_object
Disabling Floating Point Operations
Thanks to tdragon it's possible to disable
floating point operations in CMP by defining CMP_NO_FLOAT. No floating point
functionality will be included. Fair warning: this changes the ABI.
Setting Endianness at Compile Time
CMP will honor WORDS_BIGENDIAN. If defined to 0 it will convert data
to/from little-endian format when writing/reading. If defined to 1 it won't.
If not defined, CMP will check at runtime.
The core of MPack contains a buffered reader and writer, and a tree-style parser that decodes into a tree of dynamically typed nodes. Helper functions can be enabled to read values of expected type, to work with files, to grow buffers or allocate strings automatically, to check UTF-8 encoding, and more.
The MPack code is small enough to be embedded directly into your codebase. Simply download the amalgamation package and add mpack.h and mpack.c to your project.
MPack supports all modern compilers, all desktop and smartphone OSes, WebAssembly, inside the Linux kernel, and even 8-bit microcontrollers such as Arduino. The MPack featureset can be customized at compile-time to set which features, components and debug checks are compiled, and what dependencies are available.
Build Status
The Node API
The Node API parses a chunk of MessagePack data into an immutable tree of dynamically-typed nodes. A series of helper functions can be used to extract data of specific types from each node.
// parse a file into a node treempack_tree_t tree;
mpack_tree_init_filename(&tree, "homepage-example.mp", 0);
mpack_tree_parse(&tree);
mpack_node_t root = mpack_tree_root(&tree);
// extract the example data on the msgpack homepagebool compact = mpack_node_bool(mpack_node_map_cstr(root, "compact"));
int schema = mpack_node_i32(mpack_node_map_cstr(root, "schema"));
// clean up and check for errorsif (mpack_tree_destroy(&tree) != mpack_ok) {
fprintf(stderr, "An error occurred decoding the data!\n");
return;
}
Note that no additional error handling is needed in the above code. If the file is missing or corrupt, if map keys are missing or if nodes are not in the expected types, special "nil" nodes and false/zero values are returned and the tree is placed in an error state. An error check is only needed before using the data.
The above example allocates nodes automatically. A fixed node pool can be provided to the parser instead in memory-constrained environments. For maximum performance and minimal memory usage, the Expect API can be used to parse data of a predefined schema.
The Write API
The Write API encodes structured data to MessagePack.
// encode to memory bufferchar* data;
size_t size;
mpack_writer_t writer;
mpack_writer_init_growable(&writer, &data, &size);
// write the example on the msgpack homepagempack_build_map(&writer);
mpack_write_cstr(&writer, "compact");
mpack_write_bool(&writer, true);
mpack_write_cstr(&writer, "schema");
mpack_write_uint(&writer, 0);
mpack_complete_map(&writer);
// finish writingif (mpack_writer_destroy(&writer) != mpack_ok) {
fprintf(stderr, "An error occurred encoding the data!\n");
return;
}
// use the datado_something_with_data(data, size);
free(data);
In the above example, we encode to a growable memory buffer. The writer can instead write to a pre-allocated or stack-allocated buffer (with up-front sizes for compound types), avoiding the need for memory allocation. The writer can also be provided with a flush function (such as a file or socket write function) to call when the buffer is full or when writing is done.
If any error occurs, the writer is placed in an error state. The writer will flag an error if too much data is written, if the wrong number of elements are written, if an allocation failure occurs, if the data could not be flushed, etc. No additional error handling is needed in the above code; any subsequent writes are ignored when the writer is in an error state, so you don't need to check every write for errors.
The above example uses mpack_build_map() to automatically determine the number of key-value pairs contained. If you know up-front the number of elements needed, you can pass it to mpack_start_map() instead. In that case the corresponding mpack_finish_map() will assert in debug mode that the expected number of elements were actually written, which is something that other MessagePack C/C++ libraries may not do.
Comparison With Other Parsers
MPack is rich in features while maintaining very high performance and a small code footprint. Here's a short feature table comparing it to other C parsers:
A larger feature comparison table is available here which includes descriptions of the various entries in the table.
This benchmarking suite compares the performance of MPack to other implementations of schemaless serialization formats. MPack outperforms all JSON and MessagePack libraries (except CWPack), and in some tests MPack is several times faster than RapidJSON for equivalent data.
Why Not Just Use JSON?
Conceptually, MessagePack stores data similarly to JSON: they are both composed of simple values such as numbers and strings, stored hierarchically in maps and arrays. So why not just use JSON instead? The main reason is that JSON is designed to be human-readable, so it is not as efficient as a binary serialization format:
Compound types such as strings, maps and arrays are delimited, so appropriate storage cannot be allocated upfront. The whole object must be parsed to determine its size.
Strings are not stored in their native encoding. Special characters such as quotes and backslashes must be escaped when written and converted back when read.
Numbers are particularly inefficient (especially when parsing back floats), making JSON inappropriate as a base format for structured data that contains lots of numbers.
Binary data is not supported by JSON at all. Small binary blobs such as icons and thumbnails need to be Base64 encoded or passed out-of-band.
The above issues greatly increase the complexity of the decoder. Full-featured JSON decoders are quite large, and minimal decoders tend to leave out such features as string unescaping and float parsing, instead leaving these up to the user or platform. This can lead to hard-to-find platform-specific and locale-specific bugs, as well as a greater potential for security vulnerabilites. This also significantly decreases performance, making JSON unattractive for use in applications such as mobile games.
While the space inefficiencies of JSON can be partially mitigated through minification and compression, the performance inefficiencies cannot. More importantly, if you are minifying and compressing the data, then why use a human-readable format in the first place?
Testing MPack
The MPack build process does not build MPack into a library; it is used to build and run the unit tests. You do not need to build MPack or the unit testing suite to use MPack.
See test/README.md for information on how to test MPack.
CWPack is a lightweight and yet complete implementation of the
MessagePack serialization format
version 5.
It also supports the Timestamp extension type.
Excellent Performance
Together with MPack, CWPack is the fastest open-source messagepack implementation. Both totally outperform
CMP and msgpack-c
Design
CWPack does no memory allocations and no file handling in its basic setup. All that is done outside of CWPack. Example extensions are included.
CWPack is working against memory buffers. User defined handlers are called when buffers are filled up (packing) or needs refill (unpack).
Containers (arrays, maps) are read/written in parts, first the item containing the size and then the contained items one by one. Exception to this is the cw_skip_items function which skip whole containers.
Example
Pack and unpack example from the MessagePack home page:
voidexample (void)
{
cw_pack_context pc;
char buffer[20];
cw_pack_context_init (&pc, buffer, 20, 0);
cw_pack_map_size (&pc, 2);
cw_pack_str (&pc, "compact", 7);
cw_pack_boolean (&pc, true);
cw_pack_str (&pc, "schema", 6);
cw_pack_unsigned (&pc, 0);
if (pc.return_code != CWP_RC_OK) ERROR;
int length = pc.current - pc.start;
if (length != 18) ERROR;
cw_unpack_context uc;
cw_unpack_context_init (&uc, pc.start, length, 0);
if (cw_unpack_next_map_size(&uc) != 2) ERROR;
if (cw_unpack_next_str_lengh(&uc) != 7) ERROR;
if (strncmp("compact", uc.item.as.str.start, 7)) ERROR;
if (cw_unpack_next_boolean(&uc) != true) ERROR;
if (cw_unpack_next_str_lengh(&uc) != 6) ERROR;
if (strncmp("schema", uc.item.as.str.start, 6)) ERROR;
if (cw_unpack_next_signed32(&uc) != 0) ERROR;
if (uc.return_code != CWP_RC_OK) ERROR;
cw_unpack_next(&uc);
if (uc.return_code != CWP_RC_END_OF_INPUT) ERROR;
}
In the examples folder there are more examples.
Backward compatibility
CWPack may be run in compatibility mode. It affects only packing; EXT & TIMESTAMP is considered illegal, BIN are transformed to STR and generation of STR8 is supressed.
Error handling
When an error is detected in a context, the context is stopped and all future calls to that context are immediatly returned without any actions. Thus it is possible to make some calls and delay error checking until all calls are done.
CWPack does not check for illegal values (e.g. in STR for illegal unicode characters).
Build
CWPack consists of a single src file and three header files. It is written in strict ansi C and the files are together ~ 1.4K lines. No separate build is neccesary, just include the files in your own build.
CWPack has no dependencies to other libraries.
Test
Included in the test folder are a module test and a performance test and shell scripts to run them.
Objective-C
CWPack also contains an Objective-C interface. The MessagePack home page example would look like:
This is MessagePack serialization/deserialization for CLI (Common Language Infrastructure) implementations such as .NET Framework, Silverlight, Mono (including Moonlight.)
This library can be used from ALL CLS compliant languages such as C#, F#, Visual Basic, Iron Python, Iron Ruby, PowerShell, C++/CLI or so.
Usage
You can serialize/deserialize objects as following:
Create serializer via MessagePackSerializer.Get generic method. This method creates dependent types serializers as well.
Invoke serializer as following:
Pack method with destination Stream and target object for serialization.
Unpack method with source Stream.
// Creates serializer.varserializer=MessagePackSerializer.Get<T>();
// Pack obj to stream.serializer.Pack(stream, obj);
// Unpack from stream.varunpackedObject=serializer.Unpack(stream);
' Creates serializer.Dimserializer=MessagePackSerializer.Get(OfT)()' Pack obj to stream.serializer.Pack(stream,obj)' Unpack from stream.DimunpackedObject=serializer.Unpack(stream)
For production environment, you should instantiate own SerializationContext and manage its lifetime. It is good idea to treat it as singleton because SerializationContext is thread-safe.
Features
Fast and interoperable binary format serialization with simple API.
Generating pre-compiled assembly for rapid start up.
Flexible MessagePackObject which represents MessagePack type system naturally.
Note: AOT support is limited yet. Use serializer pre-generation with mpu -s utility or API.
If you do not pre-generated serializers, MsgPack for CLI uses reflection in AOT environments, it is slower and it sometimes causes AOT related error (ExecutionEngineException for runtime JIT compilation). You also have to call MessagePackSerializer.PrepareType<T> and companions in advance to avoid AOT related error. See wiki for details.
For mono, you can use net461 or net35 drops as you run with.
For Unity, unity3d drop is suitable.
How to build
For .NET Framework
Install Visual Studio 2017 (Community edition is OK) and 2015 (for MsgPack.Windows.sln).
You must install .NET Framework 3.5, 4.x, .NET Core, and Xamarin dev tools to build all builds successfully.
If you do not want to install options, edit <TargetFrameworks> element in *.csproj files to exclude platforms you want to exclude.
Or open one of above solution files in your IDE and run build command in it.
For Mono
Install latest Mono and .NET Core SDK.
Now, you can build MsgPack.sln and MsgPack.Xamarin.sln with above instructions and msbuild in latest Mono. Note that xbuild does not work because it does not support latest csproj format.
Own Unity 3D Build
First of all, there are binary drops on github release page, you should use it to save your time.
Because we will not guarantee source code organization compatibilities, we might add/remove non-public types or members, which should break source code build.
If you want to import sources, you must include just only described on MsgPack.Unity3D.csproj.
If you want to use ".NET 2.0 Subset" settings, you must use just only described on MsgPack.Unity3D.CorLibOnly.csproj file, and define CORLIB_ONLY compiler constants.
Xamarin Android testing
If you run on Windows, it is recommended to use HXM instead of Hyper-V based emulator.
You can disable Hyper-V from priviledged (administrator) powershell as follows:
Q: An error occurred while running unit test project.
A: Rebuild the project and rerun it. Or, login your Mac again, ant retry it.
Q: It is hard to read English.
A: You can read localized Xamarin docs with putting {region}-{lang} as the first component of URL path such as https://developer.xamarin.com/ja-jp/guides/....
Maintenance
MsgPack.Windows.sln
This solution contains Silverlight5 and (old) UWP project for backward compability. They are required Visual Studio 2015 to build and test.
You can download Visual Studio 2015 community edition from here.
You do not have to install Visual Studio 2015 as long as you don't edit/test/build Silverlight and/or old UWP project.
This library is a lightweight implementation of the MessagePack binary serialization format. MessagePack is a 1-to-1 binary representation of JSON, and the official specification can be found here: https://github.com/msgpack....
This library is designed to be super light weight.
Its easiest to understand how this library works if you think in terms of json. The type MPackMap represents a dictionary, and the type MPackArray represents an array.
Create MPack instances with the static method MPack.From(object);. You can pass any simple type (such as string, integer, etc), or any Array composed of a simple type. MPack also has implicit conversions from most of the basic types built in.
Transform an MPack object back into a CLR type with the static method MPack.To<T>(); or MPack.To(type);. MPack also has explicit converions going back to most basic types, you can do string str = (string)mpack; for instance.
MPack now supports native asynchrounous reading and cancellation tokens. It will not block a thread to wait on a stream.
NuGet
MPack is available as a NuGet package!
PM> Install-Package MPack
Usage
Create a object model that can be represented as MsgPack. Here we are creating a dictionary, but really it can be anything:
Serialize the data to a byte array or to a stream to be saved, transmitted, etc:
byte[] encodedBytes=dictionary.EncodeToBytes();
// -- or --dictionary.EncodeToStream(stream);
Parse the binary data back into a MPack object model (you can also cast back to an MPackMap or MPackArray after reading if you want dictionary/array methods):
varreconstructed=MPack.ParseFromBytes(encodedBytes);
// -- or --varreconstructed=MPack.ParseFromStream(stream);
Turn MPack objects back into types that we understand with the generic To<>() method. Since we know the types of everything here we can just call To<bool>() to reconstruct our bool, but if you don't know you can access the instance enum MPack.ValueType to know what kind of value it is:
Although the original was optimised for debugging and analysing, a lightweight version of the lib is included which does not keep track of all offsets and other overhead needed for debugging. It can be used in your code.
I have never run any benchmarks so I have no idea how it will perform against other implementations.
Fiddler Integration
In order to use this tool as a Fiddler plugin, copy the following files to the Fiddler Inspectors directory (usually C:\Program Files\Fiddler2\Inspectors):
MsgPackExplorer.exe
LsMsgPackFiddlerInspector.dll
LsMsgPack.dll
Restart fiddler and you should see a MsgPack option in the Inspectors list.
Source documentation
ModulesLsMsgPack.dll
This module contains the "parser" and generator of MsgPack Packages. It breaks down the binary file into a hirarchical structure, keeping track of offsets and errors. And it can also be used to generate MsgPack files.
MsgPackExplorer.exe
The main winforms executable, containing a MsgPackExplorer UserControl (so it can easily be integrated into other tools such as Fiddler).
LsMsgPackFiddlerInspector.dll
A tiny wrapper enabling the use of MsgPack Explorer as a Fiddler Inspector.
LsMsgPackUnitTests.dll
Some unit tests on the core LsMsgPack.dll. No full coverage yet, but at least it's a start.
LsMsgPackL.dll & LightUnitTests.dll
A light version of the "parser". The parsing and generating methods are almost identical to the LsMsgPack lib, but with allot of overhead removed that comes with keeping track of offsets, original types and other debugging info. I'm planning to use this version in my projects that use the MsgPack format.
The LightUnitTests are the same as LsMsgPackUnitTests with some tests omitted.
MessagePack for C# (.NET, .NET Core, Unity, Xamarin)
The extremely fast MessagePack serializer for C#.
It is 10x faster than MsgPack-Cli and outperforms other C# serializers. MessagePack for C# also ships with built-in support for LZ4 compression - an extremely fast compression algorithm. Performance is important, particularly in applications like games, distributed computing, microservices, or data caches.
This library is distributed via NuGet. Special Unity support is available, too.
We target .NET Standard 2.0 with special optimizations for .NET Core 2.1+, making it compatible with most reasonably recent .NET runtimes such as Core 2.0 and later, Framework 4.6.1 and later, Mono 5.4 and later and Unity 2018.3 and later.
The library code is pure C# (with Just-In-Time IL code generation on some platforms).
NuGet packages
To install with NuGet, just install the MessagePack package:
Install-Package MessagePack
Install the optional C# analyzers package to get warnings about coding mistakes and automatic fix suggestions to save you time:
Install-Package MessagePackAnalyzer
There are also a range of official and third party Extension Packages available (learn more in our extensions section):
For Unity projects, the releases page provides downloadable .unitypackage files. When using in Unity IL2CPP or Xamarin AOT environments, please carefully read the pre-code generation section.
Define the struct or class to be serialized and annotate it with a [MessagePackObject] attribute.
Annotate members whose values should be serialized (fields as well as properties) with [Key] attributes.
[MessagePackObject]
publicclassMyClass
{
// Key attributes take a serialization index (or string name)// The values must be unique and versioning has to be considered as well.// Keys are described in later sections in more detail.
[Key(0)]
publicintAge { get; set; }
[Key(1)]
publicstringFirstName { get; set; }
[Key(2)]
publicstringLastName { get; set; }
// All fields or properties that should not be serialized must be annotated with [IgnoreMember].
[IgnoreMember]
publicstringFullName { get { returnFirstName+LastName; } }
}
Call MessagePackSerializer.Serialize<T>/Deserialize<T> to serialize/deserialize your object instance.
You can use the ConvertToJson method to get a human readable representation of any MessagePack binary blob.
classProgram
{
staticvoidMain(string[] args)
{
varmc=newMyClass
{
Age=99,
FirstName="hoge",
LastName="huga",
};
// Call Serialize/Deserialize, that's all.byte[] bytes=MessagePackSerializer.Serialize(mc);
MyClassmc2=MessagePackSerializer.Deserialize<MyClass>(bytes);
// You can dump MessagePack binary blobs to human readable json.// Using indexed keys (as opposed to string keys) will serialize to MessagePack arrays,// hence property names are not available.// [99,"hoge","huga"]varjson=MessagePackSerializer.ConvertToJson(bytes);
Console.WriteLine(json);
}
}
Automating definitions for your serializable objects.
Produces compiler warnings upon incorrect attribute use, member accessibility, and more.
If you want to allow a specific custom type (for example, when registering a custom type), put MessagePackAnalyzer.json at the project root and change the Build Action to AdditionalFiles.
MessagePack.Nil is the built-in type representing null/void in MessagePack for C#.
Object Serialization
MessagePack for C# can serialize your own public class or struct types. By default, serializable types must be annotated with the [MessagePackObject] attribute and members with the [Key] attribute. Keys can be either indexes (int) or arbitrary strings. If all keys are indexes, arrays are used for serialization, which offers advantages in performance and binary size. Otherwise, MessagePack maps (dictionaries) will be used.
If you use [MessagePackObject(keyAsPropertyName: true)], then members do not require explicit Key attributes, but string keys will be used.
[MessagePackObject]
publicclassSample1
{
[Key(0)]
publicintFoo { get; set; }
[Key(1)]
publicintBar { get; set; }
}
[MessagePackObject]
publicclassSample2
{
[Key("foo")]
publicintFoo { get; set; }
[Key("bar")]
publicintBar { get; set; }
}
[MessagePackObject(keyAsPropertyName: true)]
publicclassSample3
{
// No need for a Key attributepublicintFoo { get; set; }
// If want to ignore a public member, you can use the IgnoreMember attribute
[IgnoreMember]
publicintBar { get; set; }
}
// [10,20]Console.WriteLine(MessagePackSerializer.SerializeToJson(newSample1 { Foo=10, Bar=20 }));
// {"foo":10,"bar":20}Console.WriteLine(MessagePackSerializer.SerializeToJson(newSample2 { Foo=10, Bar=20 }));
// {"Foo":10}Console.WriteLine(MessagePackSerializer.SerializeToJson(newSample3 { Foo=10, Bar=20 }));
All public instance members (fields as well as properties) will be serialized. If you want to ignore certain public members, annotate the member with a [IgnoreMember] attribute.
Please note that any serializable struct or class must have public accessibility; private and internal structs and classes cannot be serialized!
The default of requiring MessagePackObject annotations is meant to enforce explicitness and therefore may help write more robust code.
Should you use an indexed (int) key or a string key?
We recommend using indexed keys for faster serialization and a more compact binary representation than string keys.
However, the additional information in the strings of string keys can be quite useful when debugging.
When classes change or are extended, be careful about versioning. MessagePackSerializer will initialize members to their default value if a key does not exist in the serialized binary blob, meaning members using reference types can be initialized to null.
If you use indexed (int) keys, the keys should start at 0 and should be sequential. If a later version stops using certain members, you should keep the obsolete members (C# provides an Obsolete attribute to annotate such members) until all other clients had a chance to update and remove their uses of these members as well. Also, when the values of indexed keys "jump" a lot, leaving gaps in the sequence, it will negatively affect the binary size, as null placeholders will be inserted into the resulting arrays. However, you shouldn't reuse indexes of removed members to avoid compatibility issues between clients or when trying to deserialize legacy blobs.
If you do not want to explicitly annotate with the MessagePackObject/Key attributes and instead want to use MessagePack for C# more like e.g. Json.NET, you can make use of the contractless resolver.
publicclassContractlessSample
{
publicintMyProperty1 { get; set; }
publicintMyProperty2 { get; set; }
}
vardata=newContractlessSample { MyProperty1=99, MyProperty2=9999 };
varbin=MessagePackSerializer.Serialize(
data,
MessagePack.Resolvers.ContractlessStandardResolver.Options);
// {"MyProperty1":99,"MyProperty2":9999}Console.WriteLine(MessagePackSerializer.ConvertToJson(bin));
// You can also set ContractlessStandardResolver as the default.// (Global state; Not recommended when writing library code)MessagePackSerializer.DefaultOptions=MessagePack.Resolvers.ContractlessStandardResolver.Options;
// Now serializable...varbin2=MessagePackSerializer.Serialize(data);
If you want to serialize private members as well, you can use one of the *AllowPrivate resolvers.
[MessagePackObject]
publicclassPrivateSample
{
[Key(0)]
intx;
publicvoidSetX(intv)
{
x=v;
}
publicintGetX()
{
returnx;
}
}
vardata=newPrivateSample();
data.SetX(9999);
// You can choose either StandardResolverAllowPrivate// or ContractlessStandardResolverAllowPrivatevarbin=MessagePackSerializer.Serialize(
data,
MessagePack.Resolvers.DynamicObjectResolverAllowPrivate.Options);
If you want to use MessagePack for C# more like a BinaryFormatter with a typeless serialization API, use the typeless resolver and helpers. Please consult the Typeless section.
Resolvers are the way to add specialized support for custom types to MessagePack for C#. Please refer to the Extension point section.
DataContract compatibility
You can use [DataContract] annotations instead of [MessagePackObject] ones. If type is annotated with DataContract, you can use [DataMember] annotations instead of [Key] ones and [IgnoreDataMember] instead of [IgnoreMember].
Then [DataMember(Order = int)] will behave the same as [Key(int)], [DataMember(Name = string)] the same as [Key(string)], and [DataMember] the same as [Key(nameof(member name)].
Using DataContract, e.g. in shared libraries, makes your classes/structs independent from MessagePack for C# serialization. However, it is not supported by the analyzers nor in code generation by the mpc tool. Also, features like UnionAttribute, MessagePackFormatter, SerializationConstructor, etc can not be used. Due to this, we recommend that you use the specific MessagePack for C# annotations when possible.
Serializing readonly/immutable object members (SerializationConstructor)
MessagePack for C# supports serialization of readonly/immutable objects/members. For example, this struct can be serialized and deserialized.
MessagePackSerializer will choose the constructor with the best matched argument list, using argument indexes index for index keys, or parameter names for string keys. If it cannot determine an appropriate constructor, a MessagePackDynamicObjectResolverException: can't find matched constructor parameter exception will be thrown.
You can specify which constructor to use manually with a [SerializationConstructor] annotation.
[MessagePackObject]
publicstructPoint
{
[Key(0)]
publicreadonlyintX;
[Key(1)]
publicreadonlyintY;
[SerializationConstructor]
publicPoint(intx)
{
this.X=x;
this.Y=-1;
}
// If not marked attribute, used this(most matched argument)publicPoint(intx, inty)
{
this.X=x;
this.Y=y;
}
}
C# 9 record types
C# 9.0 record with primary constructor is similar immutable object, also supports serialize/deserialize.
// use key as property name
[MessagePackObject(true)]publicrecordPoint(int X, int Y);
// use property: to set KeyAttribute
[MessagePackObject] public record Point([property:Key(0)] intX, [property: Key(1)] intY);
// Or use explicit properties
[MessagePackObject]
publicrecordPerson
{
[Key(0)]
publicstringFirstName { get; init; }
[Key(1)]
publicstringLastName { get; init; }
}
C# 9 init property setter limitations
When using init property setters in generic classes, a CLR bug prevents our most efficient code generation from invoking the property setter.
As a result, you should avoid using init on property setters in generic classes when using the public-only DynamicObjectResolver/StandardResolver.
When using the DynamicObjectResolverAllowPrivate/StandardResolverAllowPrivate resolver the bug does not apply and you may use init without restriction.
Serialization Callback
Objects implementing the IMessagePackSerializationCallbackReceiver interface will received OnBeforeSerialize and OnAfterDeserialize calls during serialization/deserialization.
MessagePack for C# supports serializing interface-typed and abstract class-typed objects. It behaves like XmlInclude or ProtoInclude. In MessagePack for C# these are called Union. Only interfaces and abstracts classes are allowed to be annotated with Union attributes. Unique union keys are required.
Unions are internally serialized to two-element arrays.
IUnionSampledata=newBarClass { OPQ="FooBar" };
varbin=MessagePackSerializer.Serialize(data);
// Union is serialized to two-length array, [key, object]// [1,["FooBar"]]Console.WriteLine(MessagePackSerializer.ConvertToJson(bin));
Using Union with abstract classes works the same way.
Please be mindful that you cannot reuse the same keys in derived types that are already present in the parent type, as internally a single flat array or map will be used and thus cannot have duplicate indexes/keys.
Dynamic (Untyped) Deserialization
When calling MessagePackSerializer.Deserialize<object> or MessagePackSerializer.Deserialize<dynamic>, any values present in the blob will be converted to primitive values, i.e. bool, char, sbyte, byte, short, int, long, ushort, uint, ulong, float, double, DateTime, string, byte[], object[], IDictionary<object, object>.
// Sample blob.varmodel=newDynamicModel { Name="foobar", Items=new[] { 1, 10, 100, 1000 } };
varblob=MessagePackSerializer.Serialize(model, ContractlessStandardResolver.Options);
// Dynamic ("untyped")vardynamicModel=MessagePackSerializer.Deserialize<dynamic>(blob, ContractlessStandardResolver.Options);
// You can access the data using array/dictionary indexers, as shown aboveConsole.WriteLine(dynamicModel["Name"]); // foobarConsole.WriteLine(dynamicModel["Items"][2]); // 100
Exploring object trees using the dictionary indexer syntax is the fastest option for untyped deserialization, but it is tedious to read and write.
Where performance is not as important as code readability, consider deserializing with ExpandoObject.
Object Type Serialization
StandardResolver and ContractlessStandardResolver can serialize object/anonymous typed objects.
When deserializing, the behavior will be the same as Dynamic (Untyped) Deserialization.
Typeless
The typeless API is similar to BinaryFormatter, as it will embed type information into the blobs, so no types need to be specified explicitly when calling the API.
objectmc=newSandbox.MyClass()
{
Age=10,
FirstName="hoge",
LastName="huga"
};
// Serialize with the typeless APIvarblob=MessagePackSerializer.Typeless.Serialize(mc);
// Blob has embedded type-assembly information.// ["Sandbox.MyClass, Sandbox",10,"hoge","huga"]Console.WriteLine(MessagePackSerializer.ConvertToJson(bin));
// You can deserialize to MyClass again with the typeless API// Note that no type has to be specified explicitly in the Deserialize call// as type information is embedded in the binary blobvarobjModel=MessagePackSerializer.Typeless.Deserialize(bin) asMyClass;
Type information is represented by the MessagePack ext format, type code 100.
MessagePackSerializer.Typeless is a shortcut of Serialize/Deserialize<object>(TypelessContractlessStandardResolver.Instance).
If you want to configure it as the default resolver, you can use MessagePackSerializer.Typeless.RegisterDefaultResolver.
TypelessFormatter can used standalone or combined with other resolvers.
// Replaced `object` uses the typeless resolvervarresolver=MessagePack.Resolvers.CompositeResolver.Create(
new[] { MessagePack.Formatters.TypelessFormatter.Instance },
new[] { MessagePack.Resolvers.StandardResolver.Instance });
publicclassFoo
{
// use Typeless(this field only)
[MessagePackFormatter(typeof(TypelessFormatter))]
publicobjectBar;
}
If a type's name is changed later, you can no longer deserialize old blobs. But you can specify a fallback name in such cases, providing a TypelessFormatter.BindToType function of your own.
Deserializing data from an untrusted source can introduce security vulnerabilities in your application.
Depending on the settings used during deserialization, untrusted data may be able to execute arbitrary code or cause a denial of service attack.
Untrusted data might come from over the network from an untrusted source (e.g. any and every networked client) or can be tampered with by an intermediary when transmitted over an unauthenticated connection, or from a local storage that might have been tampered with, or many other sources. MessagePack for C# does not provide any means to authenticate data or make it tamper-resistant. Please use an appropriate method of authenticating data before deserialization - such as a MAC .
Please be very mindful of these attack scenarios; many projects and companies, and serialization library users in general, have been bitten by untrusted user data deserialization in the past.
When deserializing untrusted data, put MessagePack into a more secure mode by configuring your MessagePackSerializerOptions.Security property:
varoptions=MessagePackSerializerOptions.Standard
.WithSecurity(MessagePackSecurity.UntrustedData);
// Pass the options explicitly for the greatest control.Tobject=MessagePackSerializer.Deserialize<T>(data, options);
// Or set the security level as the default.MessagePackSerializer.DefaultOptions=options;
You should also avoid the Typeless serializer/formatters/resolvers for untrusted data as that opens the door for the untrusted data to potentially deserialize unanticipated types that can compromise security.
The UntrustedData mode merely hardens against some common attacks, but is no fully secure solution in itself.
Performance
Benchmarks comparing MessagePack For C# to other serializers were run on Windows 10 Pro x64 Intel Core i7-6700K 4.00GHz, 32GB RAM. Benchmark code is available here - and their version info.
ZeroFormatter and FlatBuffers have infinitely fast deserializers, so ignore their deserialization performance.
MessagePack for C# uses many techniques to improve performance.
The serializer uses IBufferWriter<byte> rather than System.IO.Stream to reduce memory overhead.
Buffers are rented from pools to reduce allocations, keeping throughput high through reduced GC pressure.
Utilize dynamic code generation and JIT to avoid boxing value types. Use AOT generation on platforms that prohibit JITs.
Cached generated formatters on static generic fields (don't use dictionary-cache because dictionary lookup is overhead). See Resolvers
Heavily tuned dynamic IL code generation and JIT to avoid boxing value types. See DynamicObjectTypeBuilder. Use AOT generation on platforms that prohibit JIT.
Call the Primitive API directly when IL code generation determines target types to be primitive.
Reduce branching of variable length formats when IL code generation knows the target type (integer/string) ranges
Don't use the IEnumerable<T> abstraction to iterate over collections when possible, see: CollectionFormatterBase and derived collection formatters
Use pre-generated lookup tables to reduce checks of mgpack type constraints, see: MessagePackBinary
Avoid string key decoding for lookup maps (string key and use automata based name lookup with inlined IL code generation, see: AutomataDictionary
To encode string keys, use pre-generated member name bytes and fixed sized byte array copies in IL, see: UnsafeMemory.cs
Before creating this library, I implemented a fast serializer with ZeroFormatter#Performance. This is a further evolved implementation. MessagePack for C# is always fast and optimized for all types (primitive, small struct, large object, any collections).
Deserialization Performance for different options
Performance varies depending on the options used. This is a micro benchmark with BenchmarkDotNet. The target object has 9 members (MyProperty1 ~ MyProperty9), values are zero.
Method
Mean
Error
Scaled
Gen 0
Allocated
M IntKey
72.67 ns
NA
1.00
0.0132
56 B
M StringKey
217.95 ns
NA
3.00
0.0131
56 B
M Typeless_IntKey
176.71 ns
NA
2.43
0.0131
56 B
M Typeless_StringKey
378.64 ns
NA
5.21
0.0129
56 B
MsgPackCliMap
1,355.26 ns
NA
18.65
0.1431
608 B
MsgPackCliArray
455.28 ns
NA
6.26
0.0415
176 B
ProtobufNet
265.85 ns
NA
3.66
0.0319
136 B
Hyperion
366.47 ns
NA
5.04
0.0949
400 B
JsonNetString
2,783.39 ns
NA
38.30
0.6790
2864 B
JsonNetStreamReader
3,297.90 ns
NA
45.38
1.4267
6000 B
JilString
553.65 ns
NA
7.62
0.0362
152 B
JilStreamReader
1,408.46 ns
NA
19.38
0.8450
3552 B
ÌntKey, StringKey, Typeless_IntKey, Typeless_StringKey are MessagePack for C# options. All MessagePack for C# options achieve zero memory allocations in the deserialization process. JsonNetString/JilString is deserialized from strings. JsonNetStreamReader/JilStreamReader is deserialized from UTF-8 byte arrays using StreamReader. Deserialization is normally read from Stream. Thus, it will be restored from byte arrays (or Stream) instead of strings.
MessagePack for C# IntKey is the fastest. StringKey is slower than IntKey because matching the character string of property names is required. IntKey works by reading the array length, then for (array length) { binary decode }. StringKey works by reading map length, for (map length) { decode key, lookup key, binary decode }, so it requires an additional two steps (decoding of keys and lookups of keys).
String key is often a useful, contractless, simple replacement of JSON, interoperability with other languages, and more robust versioning. MessagePack for C# is also optimized for string keys as much a possible. First of all, it does not decode UTF-8 byte arrays to full string for matching with the member name; instead it will look up the byte arrays as it is (to avoid decoding costs and extra memory allocations).
And It will try to match each long type (per 8 character, if it is not enough, pad with 0) using automata and inline it when generating IL code.
This also avoids calculating the hash code of byte arrays, and the comparison can be made several times faster using the long type.
This is the sample of decompiled generated deserializer code, decompiled using ILSpy.
If the number of nodes is large, searches will use an embedded binary search.
Extra note, this is serialization benchmark result.
Method
Mean
Error
Scaled
Gen 0
Allocated
IntKey
84.11 ns
NA
1.00
0.0094
40 B
StringKey
126.75 ns
NA
1.51
0.0341
144 B
Typeless_IntKey
183.31 ns
NA
2.18
0.0265
112 B
Typeless_StringKey
193.95 ns
NA
2.31
0.0513
216 B
MsgPackCliMap
967.68 ns
NA
11.51
0.1297
552 B
MsgPackCliArray
284.20 ns
NA
3.38
0.1006
424 B
ProtobufNet
176.43 ns
NA
2.10
0.0665
280 B
Hyperion
280.14 ns
NA
3.33
0.1674
704 B
ZeroFormatter
149.95 ns
NA
1.78
0.1009
424 B
JsonNetString
1,432.55 ns
NA
17.03
0.4616
1944 B
JsonNetStreamWriter
1,775.72 ns
NA
21.11
1.5526
6522 B
JilString
547.51 ns
NA
6.51
0.3481
1464 B
JilStreamWriter
778.78 ns
NA
9.26
1.4448
6066 B
Of course, IntKey is fastest but StringKey also performs reasonably well.
String interning
The msgpack format does not provide for reusing strings in the data stream.
This naturally leads the deserializer to create a new string object for every string encountered,
even if it is equal to another string previously encountered.
When deserializing data that may contain the same strings repeatedly it can be worthwhile
to have the deserializer take a little extra time to check whether it has seen a given string before
and reuse it if it has.
To enable string interning on all string values, use a resolver that specifies StringInterningFormatter
before any of the standard ones, like this:
If you know which fields of a particular type are likely to contain duplicate strings,
you can apply the string interning formatter to just those fields so the deserializer only pays
for the interned string check where it matters most.
Note that this technique requires a [MessagePackObject] or [DataContract] class.
If you are writing your own formatter for some type that contains strings,
you can call on the StringInterningFormatter directly from your formatter as well for the strings.
LZ4 Compression
MessagePack is a fast and compact format but it is not compression. LZ4 is an extremely fast compression algorithm, and using it MessagePack for C# can achieve extremely fast performance as well as extremely compact binary sizes!
MessagePack for C# has built-in LZ4 support. You can activate it using a modified options object and passing it into an API like this:
MessagePackCompression has two modes, Lz4Block and Lz4BlockArray. Neither is a simple binary LZ4 compression, but a special compression integrated into the serialization pipeline, using MessagePack ext code (Lz4BlockArray (98) or Lz4Block (99)). Therefore, it is not readily compatible with compression offered in other languages.
Lz4Block compresses an entire MessagePack sequence as a single LZ4 block. This is the simple compression that achieves best compression ratio, at the cost of copying the entire sequence when necessary to get contiguous memory.
Lz4BlockArray compresses an entire MessagePack sequence as a array of LZ4 blocks. Compressed/decompressed blocks are chunked and thus do not enter the GC's Large-Object-Heap, but the compression ratio is slightly worse.
We recommend to use Lz4BlockArray as the default when using compression.
For compatibility with MessagePack v1.x, use Lz4Block.
Regardless of which LZ4 option is set at the deserialization, both methods can be deserialized. For example, when the Lz4BlockArray option was used, binary data using either Lz4Block and Lz4BlockArray can be deserialized. Neither can be decompressed and hence deserialized when the compression option is set to None.
Attributions
LZ4 compression support is using Milosz Krajewski's lz4net code with some modifications.
Comparison with protobuf, JSON, ZeroFormatter
protobuf-net is major, widely used binary-format library on .NET. I love protobuf-net and respect their great work. But when you use protobuf-net as a general purpose serialization format, you may encounter an annoying issue.
MessagePack's type system can correctly serialize the entire C# type system. This is a strong reason to recommend MessagePack over protobuf.
Protocol Buffers have good IDL and gRPC support. If you want to use IDL, I recommend Google.Protobuf over MessagePack.
JSON is good general-purpose format. It is simple, human-readable and thoroughly-enough specified. Utf8Json - which I created as well - adopts same architecture as MessagePack for C# and avoids encoding/decoding costs as much as possible just like this library does. If you want to know more about binary vs text formats, see Utf8Json/which serializer should be used.
ZeroFormatter is similar as FlatBuffers but specialized to C#, and special in that regard. Deserialization is infinitely fast but the produced binary size is larger. And ZeroFormatter's caching algorithm requires additional memory.
For many common uses, MessagePack for C# would be a better fit.
Hints to achieve maximum performance when using MessagePack for C#
MessagePack for C# prioritizes maximum performance by default. However, there are also some options that sacrifice performance for convenience.
Use indexed keys instead of string keys (Contractless)
The Deserialization Performance for different options section shows the results of indexed keys (IntKey) vs string keys (StringKey) performance. Indexed keys serialize the object graph as a MessagePack array. String keys serializes the object graph as a MessagePack map.
IntKey is always fast in both serialization and deserialization because it does not have to handle and lookup key names, and always has the smaller binary size.
StringKey is often a useful, contractless, simple replacement for JSON, interoperability with other languages with MessagePack support, and less error prone versioning. But to achieve maximum performance, use IntKey.
Create own custom composite resolver
CompositeResolver.Create is an easy way to create composite resolvers. But formatter lookups have some overhead. If you create a custom resolver (or use StaticCompositeResolver.Instance), you can avoid this overhead.
NOTE: If you are creating a library, recommend using the above custom resolver instead of CompositeResolver.Create. Also, libraries must not use StaticCompositeResolver - as it is global state - to avoid compatibility issues.
Use native resolvers
By default, MessagePack for C# serializes GUID as string. This is much slower than the native .NET format GUID. The same applies to Decimal. If your application makes heavy use of GUID or Decimal and you don't have to worry about interoperability with other languages, you can replace them with the native serializers NativeGuidResolver and NativeDecimalResolver respectively.
Also, DateTime is serialized using the MessagePack timestamp format. By using the NativeDateTimeResolver, it is possible to maintain Kind and perform faster serialization.
Be careful when copying buffers
MessagePackSerializer.Serialize returns byte[] in default. The final byte[] is copied from an internal buffer pool. That is an extra cost. You can use IBufferWriter<T> or the Stream API to write to buffers directly. If you want to use a buffer pool outside of the serializer, you should implement custom IBufferWriter<byte> or use an existing one such as Sequence<T> from the Nerdbank.Streams package.
During deserialization, MessagePackSerializer.Deserialize(ReadOnlyMemory<byte> buffer) is better than the Deserialize(Stream stream) overload. This is because the Stream API version starts by reading the data, generating a ReadOnlySequence<byte>, and only then starts the deserialization.
Choosing compression
Compression is generally effective when there is duplicate data. In MessagePack, arrays containing objects using string keys (Contractless) can be compressed efficiently because compression can be applied to many duplicate property names. Indexed keys compression is not as effectively compressed as string keys, but indexed keys are smaller in the first place.
This is some example benchmark performance data;
Serializer
Mean
DataSize
IntKey
2.941 us
469.00 B
IntKey(Lz4)
3.449 us
451.00 B
StringKey
4.340 us
1023.00 B
StringKey(Lz4)
5.469 us
868.00 B
IntKey(Lz4) is not as effectively compressed, but performance is still somewhat degraded. On the other hand, StringKey can be expected to have a sufficient effect on the binary size. However, this is just an example. Compression can be quite effective depending on the data, too, or have little effect other than slowing down your program. There are also cases in which well-compressible data exists in the values (such as long strings, e.g. containing HTML data with many repeated HTML tags). It is important to verify the actual effects of compression on a case by case basis.
Extensions
MessagePack for C# has extension points that enable you to provide optimal serialization support for custom types. There are official extension support packages.
The MessagePack.ReactiveProperty package adds support for types of the ReactiveProperty library. It adds ReactiveProperty<>, IReactiveProperty<>, IReadOnlyReactiveProperty<>, ReactiveCollection<>, Unit serialization support. It is useful for save viewmodel state.
The MessagePack.UnityShims package provides shims for Unity's standard structs (Vector2, Vector3, Vector4, Quaternion, Color, Bounds, Rect, AnimationCurve, Keyframe, Matrix4x4, Gradient, Color32, RectOffset, LayerMask, Vector2Int, Vector3Int, RangeInt, RectInt, BoundsInt) and corresponding formatters. It can enable proper communication between servers and Unity clients.
After installation, extension packages must be enabled, by creating composite resolvers. Here is an example showing how to enable all extensions.
// Set extensions to default resolver.varresolver=MessagePack.Resolvers.CompositeResolver.Create(
// enable extension packages firstReactivePropertyResolver.Instance,
MessagePack.Unity.Extension.UnityBlitResolver.Instance,
MessagePack.Unity.UnityResolver.Instance,
// finally use standard (default) resolverStandardResolver.Instance
);
varoptions=MessagePackSerializerOptions.Standard.WithResolver(resolver);
// Pass options every time or set as defaultMessagePackSerializer.DefaultOptions=options;
The MessagePackSerializer class is the entry point of MessagePack for C#. Static methods make up the main API of MessagePack for C#.
API
Description
Serialize<T>
Serializes an object graph to a MessagePack binary blob. Async variant for Stream available. Non-generic overloads available.
Deserialize<T>
Deserializes a MessagePack binary to an object graph. Async variant for Stream available. Non-generic overloads available.
SerializeToJson
Serialize a MessagePack-compatible object graph to JSON instead of MessagePack. Useful for debugging.
ConvertToJson
Convert MessagePack binary to JSON. Useful for debugging.
ConvertFromJson
Convert JSON to a MessagePack binary.
The MessagePackSerializer.Typeless class offers most of the same APIs as above, but removes all type arguments from the API, forcing serialization to include the full type name of the root object. It uses the TypelessContractlessStandardResolver. Consider the result to be a .NET-specific MessagePack binary that isn't readily compatible with MessagePack deserializers in other runtimes.
MessagePack for C# fundamentally serializes using IBufferWriter<byte> and deserializes using ReadOnlySequence<byte> or Memory<byte>. Method overloads are provided to conveniently use it with common buffer types and the .NET Stream class, but some of these convenience overloads require copying buffers once and therefore have a certain overhead.
The high-level API uses a memory pool internally to avoid unnecessary memory allocation. If result size is under 64K, it allocates GC memory only for the return bytes.
Each serialize/deserialize method takes an optional MessagePackSerializerOptions parameter which can be used to specify a custom IFormatterResolver to use or to activate LZ4 compression support.
Multiple MessagePack structures on a single Stream
To deserialize a Stream that contains multiple consecutive MessagePack data structures,
you can use the MessagePackStreamReader class to efficiently identify the ReadOnlySequence<byte>
for each data structure and deserialize it. For example:
staticasyncTask<List<T>> DeserializeListFromStreamAsync<T>(Streamstream, CancellationTokencancellationToken)
{
vardataStructures=newList<T>();
using (varstreamReader=newMessagePackStreamReader(stream))
{
while (awaitstreamReader.ReadAsync(cancellationToken) isReadOnlySequence<byte> msgpack)
{
dataStructures.Add(MessagePackSerializer.Deserialize<T>(msgpack, cancellationToken: cancellationToken));
}
}
returndataStructures;
}
Low-Level API (IMessagePackFormatter<T>)
The IMessagePackFormatter<T> interface is responsible for serializing a unique type. For example Int32Formatter : IMessagePackFormatter<Int32> represents Int32 MessagePack serializer.
Many built-in formatters exists under MessagePack.Formatters. Your custom types are usually automatically supported with the built-in type resolvers that generate new IMessagePackFormatter<T> types on-the-fly using dynamic code generation. See our AOT code generation support for platforms that do not support this.
However, some types - especially those provided by third party libraries or the runtime itself - cannot be appropriately annotated, and contractless serialization would produce inefficient or even wrong results.
To take more control over the serialization of such custom types, write your own IMessagePackFormatter<T> implementation.
Here is an example of such a custom formatter implementation. Note its use of the primitive API that is described in the next section.
/// <summary>Serializes a <seecref="FileInfo" /> by its full path as a string.</summary>publicclassFileInfoFormatter : IMessagePackFormatter<FileInfo>
{
publicvoidSerialize(
refMessagePackWriterwriter, FileInfovalue, MessagePackSerializerOptionsoptions)
{
if (value==null)
{
writer.WriteNil();
return;
}
writer.WriteString(value.FullName);
}
publicFileInfoDeserialize(
refMessagePackReaderreader, MessagePackSerializerOptionsoptions)
{
if (reader.TryReadNil())
{
returnnull;
}
options.Security.DepthStep(refreader);
varpath=reader.ReadString();
reader.Depth--;
returnnewFileInfo(path);
}
}
The DepthStep and Depth-- statements provide a level of security while deserializing untrusted data
that might otherwise be able to execute a denial of service attack by sending MessagePack data that would
deserialize into a very deep object graph leading to a StackOverflowException that would crash the process.
This pair of statements should surround the bulk of any IMessagePackFormatter<T>.Deserialize method.
Important: A message pack formatter must read or write exactly one data structure.
In the above example we just read/write a string. If you have more than one element to write out,
you must precede it with a map or array header. You must read the entire map/array when deserializing.
For example:
publicclassMySpecialObjectFormatter : IMessagePackFormatter<MySpecialObject>
{
publicvoidSerialize(
refMessagePackWriterwriter, MySpecialObjectvalue, MessagePackSerializerOptionsoptions)
{
if (value==null)
{
writer.WriteNil();
return;
}
writer.WriteArrayHeader(2);
writer.WriteString(value.FullName);
writer.WriteString(value.Age);
}
publicMySpecialObjectDeserialize(
refMessagePackReaderreader, MessagePackSerializerOptionsoptions)
{
if (reader.TryReadNil())
{
returnnull;
}
options.Security.DepthStep(refreader);
stringfullName=null;
intage=0;
// Loop over *all* array elements independently of how many we expect,// since if we're serializing an older/newer version of this object it might// vary in number of elements that were serialized, but the contract of the formatter// is that exactly one data structure must be read, regardless.// Alternatively, we could check that the size of the array/map is what we expect// and throw if it is not.intcount=reader.ReadArrayHeader();
for (inti=0; i<count; i++)
{
switch (i)
{
case0:
fullName=reader.ReadString();
break;
case1:
age=reader.ReadInt32();
break;
default:
reader.Skip();
break;
}
}
reader.Depth--;
returnnewMySpecialObject(fullName, age);
}
}
Your custom formatters must be discoverable via some IFormatterResolver. Learn more in our resolvers section.
Primitive API (MessagePackWriter, MessagePackReader)
The MessagePackWriter and MessagePackReader structs make up the lowest-level API. They read and write the primitives types defined in the MessagePack specification.
MessagePackReader
A MessagePackReader can efficiently read from ReadOnlyMemory<byte> or ReadOnlySequence<byte> without any allocations, except to allocate a new string as required by the ReadString() method. All other methods return either value structs or ReadOnlySequence<byte> slices for extensions/arrays.
Reading directly from ReadOnlySequence<byte> means the reader can directly consume some modern high performance APIs such as PipeReader.
Method
Description
Skip
Advances the reader's position past the current value. If the value is complex (e.g. map, array) the entire structure is skipped.
Read*
Read and return a value whose type is named by the method name from the current reader position. Throws if the expected type does not match the actual type. When reading numbers, the type need not match the binary-specified type exactly. The numeric value will be coerced into the desired type or throw if the integer type is too small for a large value.
TryReadNil
Advances beyond the current value if the current value is nil and returns true; otherwise leaves the reader's position unchanged and returns false.
ReadBytes
Returns a slice of the input sequence representing the contents of a byte[], and advances the reader.
ReadStringSequence
Returns a slice of the input sequence representing the contents of a string without decoding it, and advances the reader.
Clone
Creates a new MessagePackReader with the specified input sequence and the same settings as the original reader.
CreatePeekReader
Creates a new reader with the same position as this one, allowing the caller to "read ahead" without impacting the original reader's position.
NextCode
Reads the low-level MessagePack byte that describes the type of the next value. Does not advance the reader. See MessagePack format of first byte. Its static class has ToMessagePackType and ToFormatName utility methods. MessagePackRange means Min-Max fix range of MessagePack format.
Other methods and properties as described by the .xml doc comment file and Intellisense.
The MessagePackReader is capable of automatically interpreting both the old and new MessagePack spec.
MessagePackWriter
A MessagePackWriter writes to a given instance of IBufferWriter<byte>. Several common implementations of this exist, allowing zero allocations and minimal buffer copies while writing directly to several I/O APIs including PipeWriter.
The MessagePackWriter writes the new MessagePack spec by default, but can write MessagePack compatible with the old spec by setting the OldSpec property to true.
Method
Description
Clone
Creates a new MessagePackWriter with the specified underlying IBufferWriter<byte> and the same settings as the original writer.
Flush
Writes any buffered bytes to the underlying IBufferWriter<byte>.
WriteNil
Writes the MessagePack equivalent of .NET's null value.
Write
Writes any MessagePack primitive value in the most compact form possible. Has overloads for every primitive type defined by the MessagePack spec.
Write*IntType*
Writes an integer value in exactly the MessagePack type specified, even if a more compact format exists.
WriteMapHeader
Introduces a map by specifying the number of key=value pairs it contains.
WriteArrayHeader
Introduces an array by specifying the number of elements it contains.
WriteExtensionFormat
Writes the full content of an extension value including length, type code and content.
WriteExtensionFormatHeader
Writes just the header (length and type code) of an extension value.
WriteRaw
Copies the specified bytes directly to the underlying IBufferWriter<byte> without any validation.
(others)
Other methods and properties as described by the .xml doc comment file and Intellisense.
DateTime is serialized to MessagePack Timestamp format, it serialize/deserialize UTC and loses Kind info and requires that MessagePackWriter.OldSpec == false.
If you use the NativeDateTimeResolver, DateTime values will be serialized using .NET's native Int64 representation, which preserves Kind info but may not be interoperable with non-.NET platforms.
Main Extension Point (IFormatterResolver)
An IFormatterResolver is storage of typed serializers. The MessagePackSerializer API accepts a MessagePackSerializerOptions object which specifies the IFormatterResolver to use, allowing customization of the serialization of complex types.
Resolver Name
Description
BuiltinResolver
Builtin primitive and standard classes resolver. It includes primitive(int, bool, string...) and there nullable, array and list. and some extra builtin types(Guid, Uri, BigInteger, etc...).
StandardResolver
Composited resolver. It resolves in the following order builtin -> attribute -> dynamic enum -> dynamic generic -> dynamic union -> dynamic object -> dynamic object fallback. This is the default of MessagePackSerializer.
Same as StandardResolver but allow serialize/deserialize private members.
ContractlessStandardResolverAllowPrivate
Same as ContractlessStandardResolver but allow serialize/deserialize private members.
PrimitiveObjectResolver
MessagePack primitive object resolver. It is used fallback in object type and supports bool, char, sbyte, byte, short, int, long, ushort, uint, ulong, float, double, DateTime, string, byte[], ICollection, IDictionary.
DynamicObjectTypeFallbackResolver
Serialize is used type in from object type, deserialize is used PrimitiveObjectResolver.
AttributeFormatterResolver
Get formatter from [MessagePackFormatter] attribute.
CompositeResolver
Composes several resolvers and/or formatters together in an ordered list, allowing reuse and overriding of behaviors of existing resolvers and formatters.
NativeDateTimeResolver
Serialize by .NET native DateTime binary format. It keeps DateTime.Kind that loses by standard(MessagePack timestamp) format.
NativeGuidResolver
Serialize by .NET native Guid binary representation. It is faster than standard(string) representation.
NativeDecimalResolver
Serialize by .NET native decimal binary representation. It is faster than standard(string) representation.
DynamicEnumResolver
Resolver of enum and there nullable, serialize there underlying type. It uses dynamic code generation to avoid boxing and boostup performance serialize there name.
DynamicEnumAsStringResolver
Resolver of enum and there nullable. It uses reflection call for resolve nullable at first time.
DynamicGenericResolver
Resolver of generic type(Tuple<>, List<>, Dictionary<,>, Array, etc). It uses reflection call for resolve generic argument at first time.
DynamicUnionResolver
Resolver of interface marked by UnionAttribute. It uses dynamic code generation to create dynamic formatter.
DynamicObjectResolver
Resolver of class and struct made by MessagePackObjectAttribute. It uses dynamic code generation to create dynamic formatter.
DynamicContractlessObjectResolver
Resolver of all classes and structs. It does not needs MessagePackObjectAttribute and serialized key as string(same as marked [MessagePackObject(true)]).
DynamicObjectResolverAllowPrivate
Same as DynamicObjectResolver but allow serialize/deserialize private members.
DynamicContractlessObjectResolverAllowPrivate
Same as DynamicContractlessObjectResolver but allow serialize/deserialize private members.
TypelessObjectResolver
Used for object, embed .NET type in binary by ext(100) format so no need to pass type in deserialization.
TypelessContractlessStandardResolver
Composited resolver. It resolves in the following order nativedatetime -> builtin -> attribute -> dynamic enum -> dynamic generic -> dynamic union -> dynamic object -> dynamiccontractless -> typeless. This is the default of MessagePackSerializer.Typeless
Each instance of MessagePackSerializer accepts only a single resolver. Most object graphs will need more than one for serialization, so composing a single resolver made up of several is often required, and can be done with the CompositeResolver as shown below:
// Do this once and store it for reuse.varresolver=MessagePack.Resolvers.CompositeResolver.Create(
// resolver custom types firstReactivePropertyResolver.Instance,
MessagePack.Unity.Extension.UnityBlitResolver.Instance,
MessagePack.Unity.UnityResolver.Instance,
// finally use standard resolverStandardResolver.Instance
);
varoptions=MessagePackSerializerOptions.Standard.WithResolver(resolver);
// Each time you serialize/deserialize, specify the options:byte[] msgpackBytes=MessagePackSerializer.Serialize(myObject, options);
TmyObject2=MessagePackSerializer.Deserialize<MyObject>(msgpackBytes, options);
A resolver can be set as default with MessagePackSerializer.DefaultOptions = options, but WARNING:
When developing an application where you control all MessagePack-related code it may be safe to rely on this mutable static to control behavior.
For all other libraries or multi-purpose applications that use MessagePackSerializer you should explicitly specify the MessagePackSerializerOptions to use with each method invocation to guarantee your code behaves as you expect even when sharing an AppDomain or process with other MessagePack users that may change this static property.
Here is sample of use DynamicEnumAsStringResolver with DynamicContractlessObjectResolver (It is Json.NET-like lightweight setting.)
// composite same as StandardResolvervarresolver=MessagePack.Resolvers.CompositeResolver.Create(
MessagePack.Resolvers.BuiltinResolver.Instance,
MessagePack.Resolvers.AttributeFormatterResolver.Instance,
// replace enum resolverMessagePack.Resolvers.DynamicEnumAsStringResolver.Instance,
MessagePack.Resolvers.DynamicGenericResolver.Instance,
MessagePack.Resolvers.DynamicUnionResolver.Instance,
MessagePack.Resolvers.DynamicObjectResolver.Instance,
MessagePack.Resolvers.PrimitiveObjectResolver.Instance,
// final fallback(last priority)MessagePack.Resolvers.DynamicContractlessObjectResolver.Instance
);
If you want to make an extension package, you should write both a formatter and resolver
for easier consumption.
Here is sample of a resolver:
publicclassSampleCustomResolver : IFormatterResolver
{
// Resolver should be singleton.publicstaticreadonlyIFormatterResolverInstance=newSampleCustomResolver();
privateSampleCustomResolver()
{
}
// GetFormatter<T>'s get cost should be minimized so use type cache.publicIMessagePackFormatter<T> GetFormatter<T>()
{
returnFormatterCache<T>.Formatter;
}
privatestaticclassFormatterCache<T>
{
publicstaticreadonlyIMessagePackFormatter<T> Formatter;
// generic's static constructor should be minimized for reduce type generation size!// use outer helper method.staticFormatterCache()
{
Formatter= (IMessagePackFormatter<T>)SampleCustomResolverGetFormatterHelper.GetFormatter(typeof(T));
}
}
}
internalstaticclassSampleCustomResolverGetFormatterHelper
{
// If type is concrete type, use type-formatter mapstaticreadonlyDictionary<Type, object> formatterMap=newDictionary<Type, object>()
{
{typeof(FileInfo), newFileInfoFormatter()}
// add more your own custom serializers.
};
internalstaticobjectGetFormatter(Typet)
{
objectformatter;
if (formatterMap.TryGetValue(t, outformatter))
{
returnformatter;
}
// If type can not get, must return null for fallback mechanism.returnnull;
}
}
MessagePackFormatterAttribute
MessagePackFormatterAttribute is a lightweight extension point of class, struct, interface, enum and property/field. This is like Json.NET's JsonConverterAttribute. For example, serialize private field, serialize x10 formatter.
Formatter is retrieved by AttributeFormatterResolver, it is included in StandardResolver.
IgnoreFormatter
IgnoreFormatter<T> is lightweight extension point of class and struct. If there exists types that can't be serialized, you can register IgnoreFormatter<T> that serializes those to nil/null.
// CompositeResolver can set custom formatter.varresolver=MessagePack.Resolvers.CompositeResolver.Create(
newIMessagePackFormatter[]
{
// for example, register reflection infos (can not serialize)newIgnoreFormatter<MethodBase>(),
newIgnoreFormatter<MethodInfo>(),
newIgnoreFormatter<PropertyInfo>(),
newIgnoreFormatter<FieldInfo>()
},
newIFormatterResolver[]
{
ContractlessStandardResolver.Instance
});
Reserved Extension Types
MessagePack for C# already used some MessagePack extension type codes, be careful to avoid using the same ext code for other purposes.
Range
Reserved for
[-128, -1]
Reserved by the msgpack spec for predefined types
[30, 120)
Reserved for this library's use to support common types in .NET
This leaves the following ranges for your use:
[0, 30)
[120, 127]
Within the reserved ranges, this library defines or implements extensions that use these type codes:
Code
Type
Use by
-1
DateTime
MessagePack-spec reserved for timestamp
30
Vector2[]
for Unity, UnsafeBlitFormatter
31
Vector3[]
for Unity, UnsafeBlitFormatter
32
Vector4[]
for Unity, UnsafeBlitFormatter
33
Quaternion[]
for Unity, UnsafeBlitFormatter
34
Color[]
for Unity, UnsafeBlitFormatter
35
Bounds[]
for Unity, UnsafeBlitFormatter
36
Rect[]
for Unity, UnsafeBlitFormatter
37
Int[]
for Unity, UnsafeBlitFormatter
38
Float[]
for Unity, UnsafeBlitFormatter
39
Double[]
for Unity, UnsafeBlitFormatter
98
All
MessagePackCompression.Lz4BlockArray
99
All
MessagePackCompression.Lz4Block
100
object
TypelessFormatter
Unity support
Unity lowest supported version is 2018.3, API Compatibility Level supports both .NET 4.x and .NET Standard 2.0.
You can install the unitypackage from the releases page.
If your build targets .NET Framework 4.x and runs on mono, you can use it as is.
But if your build targets IL2CPP, you can not use Dynamic***Resolver, so it is required to use pre-code generation. Please see pre-code generation section.
MessagePack for C# includes some additional System.*.dll libraries that originally provides in NuGet. They are located under Plugins. If other packages use these libraries (e.g. Unity Collections package using System.Runtime.CompilerServices.Unsafe.dll), to avoid conflicts, please delete the DLL under Plugins.
Currently CompositeResolver.Create does not work on IL2CPP, so it is recommended to use StaticCompositeResolver.Instance.Register instead.
In Unity, MessagePackSerializer can serialize Vector2, Vector3, Vector4, Quaternion, Color, Bounds, Rect, AnimationCurve, Keyframe, Matrix4x4, Gradient, Color32, RectOffset, LayerMask, Vector2Int, Vector3Int, RangeInt, RectInt, BoundsInt and their nullable, array and list types with the built-in extension UnityResolver. It is included in StandardResolver by default.
MessagePack for C# has an additional unsafe extension. UnsafeBlitResolver is special resolver for extremely fast but unsafe serialization/deserialization of struct arrays.
x20 faster Vector3[] serialization than native JsonUtility. If use UnsafeBlitResolver, serialization uses a special format (ext:typecode 30~39) for Vector2[], Vector3[], Quaternion[], Color[], Bounds[], Rect[]. If use UnityBlitWithPrimitiveArrayResolver, it supports int[], float[], double[] too. This special feature is useful for serializing Mesh (many Vector3[]) or many transform positions.
If you want to use unsafe resolver, register UnityBlitResolver or UnityBlitWithPrimitiveArrayResolver.
The MessagePack.UnityShims NuGet package is for .NET server-side serialization support to communicate with Unity. It includes shims for Vector3 etc and the Safe/Unsafe serialization extension.
If you want to share a class between Unity and a server, you can use SharedProject or Reference as Link or a glob reference (with LinkBase), etc. Anyway, you need to share at source-code level. This is a sample project structure using a glob reference (recommended).
[MessagePack](not dll/NuGet, use MessagePack.Unity.unitypackage's sourcecode)
AOT Code Generation (support for Unity/Xamarin)
By default, MessagePack for C# serializes custom objects by generating IL on the fly at runtime to create custom, highly tuned formatters for each type. This code generation has a minor upfront performance cost.
Because strict-AOT environments such as Xamarin and Unity IL2CPP forbid runtime code generation, MessagePack provides a way for you to run a code generator ahead of time as well.
Note: When using Unity, dynamic code generation only works when targeting .NET Framework 4.x + mono runtime.
For all other Unity targets, AOT is required.
If you want to avoid the upfront dynamic generation cost or you need to run on Xamarin or Unity, you need AOT code generation. mpc (MessagePackCompiler) is the code generator of MessagePack for C#. mpc uses Roslyn to analyze source code.
First of all, mpc requires .NET Core 3 Runtime. The easiest way to acquire and run mpc is as a dotnet tool.
Installing it as a local tool allows you to include the tools and versions that you use in your source control system. Run these commands in the root of your repo:
dotnet new tool-manifest
dotnet tool install MessagePack.Generator
Check in your .config\dotnet-tools.json file. On another machine you can "restore" your tool using the dotnet tool restore command.
Once you have the tool installed, simply invoke using dotnet mpc within your repo:
dotnet mpc --help
Alternatively, you can download mpc from the releases page, that includes platform native binaries (that don't require a separate dotnet runtime).
Usage: mpc [options...]
Options:
-i, -input <String> Input path to MSBuild project file or the directory containing Unity source files. (Required)
-o, -output <String> Output file path(.cs) or directory(multiple generate file). (Required)
-c, -conditionalSymbol <String> Conditional compiler symbols, split with ','. (Default: null)
-r, -resolverName <String> Set resolver name. (Default: GeneratedResolver)
-n, -namespace <String> Set namespace root name. (Default: MessagePack)
-m, -useMapMode <Boolean> Force use map mode serialization. (Default: False)
-ms, -multipleIfDirectiveOutputSymbols <String> Generate #if-- files by symbols, split with ','. (Default: null)
mpc targets C# code with [MessagePackObject] or [Union] annotations.
In Unity, you can use MessagePack CodeGen windows at Windows -> MessagePack -> CodeGenerator.
Install the .NET Core runtime, install mpc (as a .NET Core Tool as described above), and execute dotnet mpc. Currently this tool is experimental so please tell me your opinion.
In Xamarin, you can install the the MessagePack.MSBuild.Tasks NuGet package into your projects to pre-compile fast serialization code and run in environments where JIT compilation is not allowed.
RPC
MessagePack advocated MessagePack RPC, but work on it has stopped and it is not widely used.
MagicOnion
I've created a gRPC based MessagePack HTTP/2 RPC streaming framework called MagicOnion. gRPC usually communicates with Protocol Buffers using IDL. But MagicOnion uses MessagePack for C# and does not need IDL. When communicating C# to C#, schemaless (or rather C# classes as schema) is better than using IDL.
Yoshifumi Kawai (a.k.a. neuecc) is a software developer in Japan.
He is the Director/CTO at Grani, Inc.
Grani is a mobile game developer company in Japan and well known for using C#.
He is awarding Microsoft MVP for Visual C# since 2011.
He is known as the creator of UniRx (Reactive Extensions for Unity)
msgpack11 is a tiny MsgPack library for C++11, providing MsgPack parsing and serialization.
This library is inspired by json11.
The API of msgpack11 is designed to be similar with json11.
Installation
Using CMake
git clone [email protected]:ar90n/msgpack11.git
mkdir build
cd build
cmake ../msgpack11
make && make install
Using Buck
git clone [email protected]:ar90n/msgpack11.git
cd msgpack11
buck build :msgpack11
A modern (c++17 required) implementation of the msgpack spec.
Msgpack is a binary serialization specification. It allows you to save and load application objects like classes and structs over networks, to files, and between programs and even different languages.
Check out this blog for my rational creating this library.
Features
Fast and compact
Full test coverage
Easy to use
Automatic type handling
Open source MIT license
Easy error handling
Single Header only template library
Want to use this library? Just #include the header and you're good to go. Its less than 1000 lines of code.
Cereal style packaging
Easily pack objects into byte arrays using a pack free function:
structPerson {
std::string name;
uint16_t age;
std::vector<std::string> aliases;
template<classT>
voidmsgpack(T &pack) {
pack(name, age, aliases);
}
};
intmain() {
auto person = Person{"John", 22, {"Ripper", "Silverhand"}};
auto data = msgpack::pack(person); // Pack your objectauto john = msgpack::unpack<Person>(data.data()); // Unpack it
}
The msgpack spec allows for additional types to be enumerated as Extensions. If reasonable use cases come about for this feature then it may be added.
Name/value pairs
The msgpack spec uses the 'map' type differently than this library. This library implements maps in which key/value pairs must all have the same value types.
Endian conversion shortcuts
On platforms that already hold types in big endian, the serialization could be optimized using type traits.
MessagePack is an efficient binary serialization
format, which lets you exchange data among multiple languages like JSON,
except that it's faster and smaller. Small integers are encoded into a
single byte and short strings require only one extra byte in
addition to the strings themselves.
clojure-msgpack is a lightweight and simple library for converting
between native Clojure data structures and MessagePack byte formats.
clojure-msgpack only depends on Clojure itself; it has no third-party
dependencies.
Installation
Usage
Basic
pack: Serialize object as a sequence of java.lang.Bytes.
clojure-msgpack provides a streaming API for situations where it is more
convenient or efficient to work with byte streams instead of fixed byte arrays
(e.g. size of object is not known ahead of time).
The streaming counterpart to msgpack.core/pack is msgpack.core/pack-stream
which returns nil and accepts either
java.io.OutputStream
or
java.io.DataOutput
as an additional argument.
Serializing a value of unrecognized type will fail with IllegalArgumentException. See Application types if you want to register your own types.
Clojure types
Some native Clojure types don't have an obvious MessagePack counterpart. We can
serialize them as Extended types. To enable automatic conversion of these
types, load the clojure-extensions library.
(msg/pack:hello)
; => IllegalArgumentException No implementation of method: :pack-stream of; protocol: #'msgpack.core/Packable found for class: clojure.lang.Keyword; clojure.core/-cache-protocol-fn (core _deftype.clj:544)
Note: No error is thrown if an unpacked value is reserved under the old spec
but defined under the new spec. We always deserialize something if we can
regardless of compatibility-mode.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License You may obtain a copy of the License at
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
MessagePack is a binary-based JSON-like serialization library.
MessagePack for D is a pure D implementation of MessagePack.
Features
Small size and High performance
Zero copy serialization / deserialization
Streaming deserializer for non-contiguous IO situation
Supports D features (Ranges, Tuples, real type)
Note: The real type is only supported in D.
Don't use the real type when communicating with other programming languages.
Note that Unpacker will raise an exception if a loss of precision occurs.
Current Limitations
No circular references support
If you want to use the LDC compiler, you need at least version 0.15.2 beta2
Install
Use dub to add it as a dependency:
% dub install msgpack-d
Usage
Example code can be found in the example directory.
msgpack-d is very simple to use. Use pack for serialization, and unpack for deserialization:
importstd.file;
import msgpack;
structS { int x; float y; string z; }
voidmain()
{
S input = S(10, 25.5, "message");
// serialize dataubyte[] inData = pack(input);
// write data to a file
write("file.dat", inData);
// read data from a fileubyte[] outData = cast(ubyte[])read("file.dat");
// unserialize the data
S target = outData.unpack!S();
// verify data is the sameassert(target.x == input.x);
assert(target.y == input.y);
assert(target.z == input.z);
}
Feature: Skip serialization/deserialization of a specific field.
Use the @nonPacked attribute:
structUser
{
string name;
@nonPacked int level; // pack / unpack will ignore the 'level' field
}
Feature: Use your own serialization/deserialization routines for custom class and struct types.
msgpack-d provides the functions registerPackHandler / registerUnpackHandler to allow you
to use custom routines during the serialization or deserialization of user-defined class and struct types.
This feature is especially useful when serializing a derived class object when that object is statically
typed as a base class object.
For example:
classDocument { }
classXmlDocument : Document
{
this() { }
this(string name) { this.name = name; }
string name;
}
voidxmlPackHandler(ref Packer p, ref XmlDocument xml)
{
p.pack(xml.name);
}
voidxmlUnpackHandler(ref Unpacker u, ref XmlDocument xml)
{
u.unpack(xml.name);
}
voidmain()
{
/// Register the 'xmlPackHandler' and 'xmlUnpackHandler' routines for/// XmlDocument object instances.
registerPackHandler!(XmlDocument, xmlPackHandler);
registerUnpackHandler!(XmlDocument, xmlUnpackHandler);
/// Now we can serialize/deserialize XmlDocument object instances via a/// base class reference.Document doc = new XmlDocument("test.xml");
auto data = pack(doc);
XmlDocument xml = unpack!XmlDocument(data);
assert(xml.name =="test.xml"); // xml.name is "test.xml"
}
In addition, here is also a method using @serializedAs attribute:
QMsgPack is a simple and powerful Delphi & C++ Builder implementation for messagepack protocol.
QMsgPack is a part of QDAC 3.0,Source code hosted in Sourceforge(http://sourceforge.net/p/qdac3).
Feathers
· Full types support,include messagepack extension type
· Full open source,free for used in ANY PURPOSE
· Quick and simple interface
· RTTI support include
Install
QMsgPack is not a desgin time package.So just place QMsgPack files into search path and add to your project.
Only in packing. Atoms are packed as binaries. Default value is pack.
Otherwise, any term including atoms throws badarg.
{known_atoms, [atom()]}
Both in packing and unpacking. In packing, if an atom is in this list
a binary is encoded as a binary. In unpacking, msgpacked binaries are
decoded as atoms with erlang:binary_to_existing_atom/2 with encoding
utf8. Default value is an empty list.
Even if allow_atom is none, known atoms are packed.
{unpack_str, as_binary|as_list}
A switch to choose decoded term style of str type when unpacking.
Only available at new spec. Default is as_list.
mode as_binary as_list
-----------+------------+-------
bin binary() binary()
str binary() string()
{validate_string, boolean()}
Only in unpacking, UTF-8 validation at unpacking from str type will
be enabled. Default value is false.
{pack_str, from_binary|from_list|none}
A switch to choose packing of string() when packing. Only available
at new spec. Default is from_list for symmetry with unpack_str
option.
mode from_list from_binary none
-----------+------------+--------------+-----------------
binary() bin str*/bin bin
string() str*/array array of int array of int
list() array array array
But the default option pays the cost of performance for symmetry. If
the overhead of UTF-8 validation is unacceptable, choosing none as
the option would be the best.
* Tries to pack as str if it is a valid string().
{map_format, map|jiffy|jsx}
Both at packing and unpacking. Default value is map.
At both. The default behaviour in case of facing ext data at decoding
is to ignore them as its length is known.
Now msgpack-erlang supports ext type. Now you can serialize everything
with your original (de)serializer. That will enable us to handle
erlang- native types like pid(), ref() contained in tuple(). See
test/msgpack_ext_example_tests.erl for example code.
The Float type of Message Pack represents IEEE 754 floating point number, so it includes Nan and Infinity.
In unpacking, msgpack-erlang returns nan, positive_infinity and negative_infinity.
License
Apache License 2.0
Release Notes
0.7.0
Support nan, positive_infinity and negative_infinity
0.6.0
Support OTP 19.0
0.5.0
Renewed optional arguments to pack/unpack interface. This is
incompatible change from 0.4 series.
0.4.0
Deprecate nil
Moved to rebar3
Promote default map unpacker as default format when OTP is >= 17
Added QuickCheck tests
Since this version OTP older than R16B03-1 are no more supported
0.3.5 / 0.3.4
0.3 series will be the last versions that supports R16B or older
versions of OTP.
OTP 18.0 support
Promote default map unpacker as default format when OTP is >= 18
0.3.3
Add OTP 17 series to Travis-CI tests
Fix wrong numbering for ext types
Allow packing maps even when {format,map} is not set
Fix Dialyzer invalid contract warning
Proper use of null for jiffy-style encoding/decoding
0.3.2
set back default style as jiffy
fix bugs around nil/null handling
0.3.0
supports map new in 17.0
jiffy-style maps will be deprecated in near future
set default style as map
0.2.8
0.2 series works with OTP 17.0, R16, R15, and with MessagePack's new
and old format. But does not support map type introduced in
OTP 17.0.
msgpack is brought to you by ⭐uptrace/uptrace.
Uptrace is an open source and blazingly fast
distributed tracing tool powered
by OpenTelemetry and ClickHouse. Give it a star as well!
Field names can be set in much the same way as the encoding/json package. For example:
typePersonstruct {
Namestring`msg:"name"`Addressstring`msg:"address"`Ageint`msg:"age"`Hiddenstring`msg:"-"`// this field is ignoredunexportedbool// this field is also ignored
}
By default, the code generator will satisfy msgp.Sizer, msgp.Encodable, msgp.Decodable,
msgp.Marshaler, and msgp.Unmarshaler. Carefully-designed applications can use these methods to do
marshalling/unmarshalling with zero heap allocations.
While msgp.Marshaler and msgp.Unmarshaler are quite similar to the standard library's
json.Marshaler and json.Unmarshaler, msgp.Encodable and msgp.Decodable are useful for
stream serialization. (*msgp.Writer and *msgp.Reader are essentially protocol-aware versions
of *bufio.Writer and *bufio.Reader, respectively.)
Features
Extremely fast generated code
Test and benchmark generation
JSON interoperability (see msgp.CopyToJSON() and msgp.UnmarshalAsJSON())
Support for complex type declarations
Native support for Go's time.Time, complex64, and complex128 types
Generation of both []byte-oriented and io.Reader/io.Writer-oriented methods
As long as the declarations of MyInt and Data are in the same file as Struct, the parser will determine that the type information for MyInt and Data can be passed into the definition of Struct before its methods are generated.
Extensions
MessagePack supports defining your own types through "extensions," which are just a tuple of
the data "type" (int8) and the raw binary. You can see a worked example in the wiki.
Status
Mostly stable, in that no breaking changes have been made to the /msgp library in more than a year. Newer versions
of the code may generate different code than older versions for performance reasons. I (@philhofer) am aware of a
number of stability-critical commercial applications that use this code with good results. But, caveat emptor.
You can read more about how msgp maps MessagePack types onto Go types in the wiki.
Here some of the known limitations/restrictions:
Identifiers from outside the processed source file are assumed (optimistically) to satisfy the generator's interfaces. If this isn't the case, your code will fail to compile.
Like most serializers, chan and func fields are ignored, as well as non-exported fields.
Encoding of interface{} is limited to built-ins or types that have explicit encoding methods.
Maps must have string keys. This is intentional (as it preserves JSON interop.) Although non-string map keys are not forbidden by the MessagePack standard, many serializers impose this restriction. (It also means any well-formed struct can be de-serialized into a map[string]interface{}.) The only exception to this rule is that the deserializers will allow you to read map keys encoded as bin types, due to the fact that some legacy encodings permitted this. (However, those values will still be cast to Go strings, and they will be converted to str types when re-encoded. It is the responsibility of the user to ensure that map keys are UTF-8 safe in this case.) The same rules hold true for JSON translation.
If the output compiles, then there's a pretty good chance things are fine. (Plus, we generate tests for you.) Please, please, please file an issue if you think the generator is writing broken code.
As one might expect, the generated methods that deal with []byte are faster for small objects, but the io.Reader/Writer methods are generally more memory-efficient (and, at some point, faster) for large (> 2KB) objects.
If your application serializes only primitive types, array, map and struct, code generation is also recommended.
You can get the fastest performance with msgpackgen.
Msgpack for HHVM, It is a msgpack binding for HHVM
API
msgpack_pack(mixed $input) : string;
pack a input to msgpack, object and resource are not supported, array and other types supported,
false on failure.
msgpack_unpack(string $pac) : mixed;
unpack a msgpack.
Installation
$ git clone https://github.com/reeze/msgpack-hhvm --depth=1
$ cd msgpack-hhvm
$ hphpize && cmake .&& make
$ cp msgpack.so /path/to/your/hhvm/ext/dir
If you don't have hphpize program, please intall package hhvm-dev
This Jackson extension library handles reading and writing of data encoded in MessagePack data format.
It extends standard Jackson streaming API (JsonFactory, JsonParser, JsonGenerator), and as such works seamlessly with all the higher level data abstractions (data binding, tree model, and pluggable extensions).
Maven dependency
To use this module on Maven-based projects, use following dependency:
MessagePack is a binary serialization format. If you need a fast and compact alternative of JSON, MessagePack is your friend. For example, a small integer can be encoded in a single byte, and short strings only need a single byte prefix + the original byte array. MessagePack implementation is already available in various languages (See also the list in http://msgpack.org) and works as a universal data format.
MessagePack v7 (or later) is a faster implementation of the previous version v06, and
supports all of the message pack types, including extension format.
Integration with Jackson ObjectMapper (jackson-databind)
msgpack-java supports serialization and deserialization of Java objects through jackson-databind.
For details, see msgpack-jackson/README.md. The template-based serialization mechanism used in v06 is deprecated.
Here is a list of sbt commands for daily development:
> ~compile # Compile source codes
> ~test:compile # Compile both source and test codes
> ~test # Run tests upon source code change
> ~testOnly *MessagePackTest # Run tests in the specified class
> ~testOnly *MessagePackTest -- (pattern) # Run tests matching the pattern
> project msgpack-core # Focus on a specific project
> package # Create a jar file in the target folder of each project
> findbugs # Produce findbugs report in target/findbugs
> jacoco:cover # Report the code coverage of tests to target/jacoco folder
> jcheckStyle # Run check style
> ;scalafmt;test:scalafmt;scalafmtSbt # Reformat Scala codes
Publishing
> publishLocal # Install to local .ivy2 repository
> publishM2 # Install to local .m2 Maven repository
> publish # Publishing a snapshot version to the Sonatype repository
Publish to Sonatype (Maven Central)
To publish a new version, you only need to add a new git tag and push it to GitHub. GitHub Action will deploy a new release version to Maven Central (Sonatype).
$ git tag v0.x.y
$ git push origin v0.x.y
To generate a release notes, you can use this command line:
If you need to publish to Maven central using a local machine, you need to configure sbt-sonatype plugin. First set Sonatype account information (user name and password) in the global sbt settings. To protect your password, never include this file in your project.
You may also need to configure GPG. See the instruction in sbt-pgp.
Then, run publishedSigned followed by sonatypeBundleRelease:
# [optional] When you need to perform the individual release steps manually, use the following commands:
> publishSigned # Publish GPG signed artifacts to the Sonatype repository
> sonatypeBundleRelease # Publish to the Maven Central (It will be synched within less than 4 hours)
If some sporadic error happens (e.g., Sonatype timeout), rerun sonatypeBundleRelease again.
Project Structure
msgpack-core # Contains packer/unpacker implementation that never uses third-party libraries
msgpack-jackson # Contains jackson-dataformat-java implementation
Pure JavaScript only (No node-gyp nor gcc required)
Faster than any other pure JavaScript libraries on node.js v4
Even faster than node-gyp C++ based msgpack library (90% faster on encoding)
Streaming encoding and decoding interface is also available. It's more faster.
Ready for Web browsers including Chrome, Firefox, Safari and even IE8
Tested on Node.js v0.10, v0.12, v4, v5 and v6 as well as Web browsers
Encoding and Decoding MessagePack
varmsgpack=require("msgpack-lite");// encode from JS Object to MessagePack (Buffer)varbuffer=msgpack.encode({"foo": "bar"});// decode from MessagePack (Buffer) to JS Objectvardata=msgpack.decode(buffer);// => {"foo": "bar"}// if encode/decode receives an invalid argument an error is thrown
Writing to MessagePack Stream
varfs=require("fs");varmsgpack=require("msgpack-lite");varwriteStream=fs.createWriteStream("test.msp");varencodeStream=msgpack.createEncodeStream();encodeStream.pipe(writeStream);// send multiple objects to streamencodeStream.write({foo: "bar"});encodeStream.write({baz: "qux"});// call this once you're done writing to the stream.encodeStream.end();
Reading from MessagePack Stream
varfs=require("fs");varmsgpack=require("msgpack-lite");varreadStream=fs.createReadStream("test.msp");vardecodeStream=msgpack.createDecodeStream();// show multiple objects decoded from streamreadStream.pipe(decodeStream).on("data",console.warn);
Decoding MessagePack Bytes Array
varmsgpack=require("msgpack-lite");// decode() accepts Buffer instance per defaultmsgpack.decode(Buffer([0x81,0xA3,0x66,0x6F,0x6F,0xA3,0x62,0x61,0x72]));// decode() also accepts Array instancemsgpack.decode([0x81,0xA3,0x66,0x6F,0x6F,0xA3,0x62,0x61,0x72]);// decode() accepts raw Uint8Array instance as wellmsgpack.decode(newUint8Array([0x81,0xA3,0x66,0x6F,0x6F,0xA3,0x62,0x61,0x72]));
Command Line Interface
A CLI tool bin/msgpack converts data stream from JSON to MessagePack and vice versa.
Proceed to the next steps if you prefer faster browserify compilation time.
Step #2: add browser property on package.json in your project. This refers the global msgpack object instead of including whole of msgpack-lite source code.
A benchmark tool lib/benchmark.js is available to compare encoding/decoding speed
(operation per second) with other MessagePack modules.
It counts operations of 1KB JSON document in 10 seconds.
Streaming benchmark tool lib/benchmark-stream.js is also available.
It counts milliseconds for 1,000,000 operations of 30 bytes fluentd msgpack fragment.
This shows streaming encoding and decoding are super faster.
$ npm run benchmark-stream 2
operation (1000000 x 2)
op
ms
op/s
stream.write(msgpack.encode(obj));
1000000
3027
330360
stream.write(notepack.encode(obj));
1000000
2012
497017
msgpack.Encoder().on("data",ondata).encode(obj);
1000000
2956
338294
msgpack.createEncodeStream().write(obj);
1000000
1888
529661
stream.write(msgpack.decode(buf));
1000000
2020
495049
stream.write(notepack.decode(buf));
1000000
1794
557413
msgpack.Decoder().on("data",ondata).decode(buf);
1000000
2744
364431
msgpack.createDecodeStream().write(buf);
1000000
1341
745712
Test environment: msgpack-lite 0.1.14, Node v4.2.3, Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz
MessagePack Mapping Table
The following table shows how JavaScript objects (value) will be mapped to
MessagePack formats
and vice versa.
Source Value
MessagePack Format
Value Decoded
null, undefined
nil format family
null
Boolean (true, false)
bool format family
Boolean (true, false)
Number (32bit int)
int format family
Number (int or double)
Number (64bit double)
float format family
Number (double)
String
str format family
String
Buffer
bin format family
Buffer
Array
array format family
Array
Map
map format family
Map (if usemap=true)
Object (plain object)
map format family
Object (or Map if usemap=true)
Object (see below)
ext format family
Object (see below)
Note that both null and undefined are mapped to nil 0xC1 type.
This means undefined value will be upgraded to null in other words.
Extension Types
The MessagePack specification allows 128 application-specific extension types.
The library uses the following types to make round-trip conversion possible
for JavaScript native objects.
Type
Object
Type
Object
0x00
0x10
0x01
EvalError
0x11
Int8Array
0x02
RangeError
0x12
Uint8Array
0x03
ReferenceError
0x13
Int16Array
0x04
SyntaxError
0x14
Uint16Array
0x05
TypeError
0x15
Int32Array
0x06
URIError
0x16
Uint32Array
0x07
0x17
Float32Array
0x08
0x18
Float64Array
0x09
0x19
Uint8ClampedArray
0x0A
RegExp
0x1A
ArrayBuffer
0x0B
Boolean
0x1B
Buffer
0x0C
String
0x1C
0x0D
Date
0x1D
DataView
0x0E
Error
0x1E
0x0F
Number
0x1F
Other extension types are mapped to built-in ExtBuffer object.
Custom Extension Types (Codecs)
Register a custom extension type number to serialize/deserialize your own class instances.
The first argument of addExtPacker and addExtUnpacker should be an integer within the range of 0 and 127 (0x0 and 0x7F). myClassPacker is a function that accepts an instance of MyClass, and should return a buffer representing that instance. myClassUnpacker is the opposite: it accepts a buffer and should return an instance of MyClass.
If you pass an array of functions to addExtPacker or addExtUnpacker, the value to be encoded/decoded will pass through each one in order. This allows you to do things like this:
You can also pass the codec option to msgpack.Decoder(options), msgpack.Encoder(options), msgpack.createEncodeStream(options), and msgpack.createDecodeStream(options).
If you wish to modify the default built-in codec, you can access it at msgpack.codec.preset.
Custom Codec Options
msgpack.createCodec() function accepts some options.
It does NOT have the preset extension types defined when no options given.
varcodec=msgpack.createCodec();
preset: It has the preset extension types described above.
varcodec=msgpack.createCodec({preset: true});
safe: It runs a validation of the value before writing it into buffer. This is the default behavior for some old browsers which do not support ArrayBuffer object.
varcodec=msgpack.createCodec({safe: true});
useraw: It uses raw formats instead of bin and str.
varcodec=msgpack.createCodec({useraw: true});
int64: It decodes msgpack's int64/uint64 formats with int64-buffer object.
varcodec=msgpack.createCodec({int64: true});
binarraybuffer: It ties msgpack's bin format with ArrayBuffer object, instead of Buffer object.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
This is a MessagePack serializer and deserializer written in JavaScript for web browsers (including IE 11) and Node.js.
It is compact but still fully-featured. This library supports the complete MessagePack specification released on 2017-08-09, including date/time values. No other extension types are implemented in this library, it’s only the standard types which is perfectly fine for interoperability with MessagePack codecs in other programming languages.
I’m using the MessagePack-CSharp library on the server side in my .NET applications.
MessagePack
MessagePack is an efficient binary serialisation format. It lets you exchange data among multiple languages like JSON. But it’s faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves.
Size
This library is very lightweight. The source code has around 560 lines (incl. browser/Node detection), the minified file has 7.0 kB and can be GZip-compressed to 2.7 kB.
Performance
The file msgpack-tests.html contains some tests and a benchmark function that compares this library with msgpack-lite. Here are the results, in milliseconds (lower is better). All tests done on an Intel Core i7-3770 and Windows 10.
Function
Chrome 72
Firefox 65
Edge 16
IE 11
msgpack.js serialize
702 ms
+6%
1232 ms
−42%
2483 ms
+41%
2493 ms
−3%
msgpack-lite encode
663 ms
2124 ms
1762 ms
2578 ms
msgpack.js deserialize
652 ms
+13%
869 ms
+5%
821 ms
−48%
651 ms
−68%
msgpack-lite decode
577 ms
827 ms
1587 ms
2021 ms
The numbers show that this library is comparable with msgpack-lite. In Chrome it’s only 10% slower. But serializing in Firefox and deserializing in Microsoft browsers is twice as fast.
Usage
Browser
In browsers, a global msgpack object is created that contains the functions serialize and deserialize. The first can be called with any data and returns the serialized bytes. The second works in reverse, taking the serialized bytes and returning the runtime value.
Include the JavaScript file into your HTML document like this:
<scriptsrc="msgpack.min.js"></script>
You can use the library functions after loading the script.
If there should be a naming conflict with another library you want to load, you can change the global object name from msgpack to something else by setting msgpackJsName before loading the script file:
In Node.js, these functions are exported in the object you get from the require function.
varmsgpack=require("@ygoe/msgpack");
Example
Here’s a simple example:
// Define some datavarsourceData={number: 123,number2: -0.129,text: "Abc with Üñıçôðé and ユニコード",flag: true,list: [1,2,3],obj: {a: 1,b: "2",c: false,d: {a: 0,b: -1}},time: Date.now()};// Serialize to byte arrayvarbytes=msgpack.serialize(sourceData);// Deserialize againvardeserializedData=msgpack.deserialize(bytes);
Compatibility
You can also use the functions encode and decode which are aliases to serialize and deserialize. This makes it easier to replace other libraries that use these function names with msgpack.js.
New projects should use the preferred (and more precisely named) serialize and deserialize functions though.
The msgpackr package is an extremely fast MessagePack NodeJS/JavaScript implementation. Currently, it is significantly faster than any other known implementations, faster than Avro (for JS), and generally faster than native V8 JSON.stringify/parse, on NodeJS. It also includes an optional record extension (the r in msgpackr), for defining record structures that makes MessagePack even faster and more compact, often over twice as fast as even native JSON functions, several times faster than other JS implementations, and 15-50% more compact. See the performance section for more details. Structured cloning (with support for cyclical references) is also supported through optional extensions.
Basic Usage
Install with:
npm i msgpackr
And import or require it for basic standard serialization/encoding (pack) and deserialization/decoding (unpack) functions:
This pack function will generate standard MessagePack without any extensions that should be compatible with any standard MessagePack parser/decoder. It will serialize JavaScript objects as MessagePack maps by default. The unpack function will deserialize MessagePack maps as an Object with the properties from the map.
Node Usage
The msgpackr package runs on any modern JS platform, but is optimized for NodeJS usage (and will use a node addon for performance boost as an optional dependency).
Streams
We can use the including streaming functionality (which further improves performance). The PackrStream is a NodeJS transform stream that can be used to serialize objects to a binary stream (writing to network/socket, IPC, etc.), and the UnpackrStream can be used to deserialize objects from a binary sream (reading from network/socket, etc.):
Or for a full example of sending and receiving data on a stream:
import{PackrStream,UnpackrStream}from'msgpackr';letsendingStream=newPackrStream();letreceivingStream=newUnpackrStream();// we are just piping to our own stream, but normally you would send and// receive over some type of inter-process or network connection.sendingStream.pipe(receivingStream);sendingStream.write(myData);receivingStream.on('data',(data)=>{// received data});
The PackrStream and UnpackrStream instances will have also the record structure extension enabled by default (see below).
Deno Usage
Msgpackr modules are standard ESM modules and can be loaded directly from the deno.land registry for msgpackr for use in Deno. The standard pack/encode and unpack/decode functionality is available on Deno, like other platforms.
Browser Usage
Msgpackr works as standalone JavaScript as well, and runs on modern browsers. It includes a bundled script, at dist/index.js for ease of direct loading:
This is UMD based, and will register as a module if possible, or create a msgpackr global with all the exported functions.
For module-based development, it is recommended that you directly import the module of interest, to minimize dependencies that get pulled into your application:
import{unpack}from'msgpackr/unpack'// if you only need to unpack
The package also includes a minified bundle in index.min.js.
Additionally, the package includes a version that excludes dynamic code evaluation called index-no-eval.js, for situations where Content Security Policy (CSP) forbids eval/Function in code. The dynamic evaluation provides important performance optimizations (for records), so is not recommended unless required by CSP policy.
Structured Cloning
You can also use msgpackr for structured cloning. By enabling the structuredClone option, you can include references to other objects or cyclic references, and object identity will be preserved. Structured cloning also enables preserving certain typed objects like Error, Set, RegExp and TypedArray instances. For example:
This option is disabled by default because it uses extensions and reference checking degrades performance (by about 25-30%). (Note this implementation doesn't serialize every class/type specified in the HTML specification since not all of them make sense for storing across platforms.)
Alternate Terminology
If you prefer to use encoder/decode terminology, msgpackr exports aliases, so decode is equivalent to unpack, encode is pack, Encoder is Packr, Decoder is Unpackr, and EncoderStream and DecoderStream can be used as well.
Record / Object Structures
There is a critical difference between maps (or dictionaries) that hold an arbitrary set of keys and values (JavaScript Map is designed for these), and records or object structures that have a well-defined set of fields. Typical JS objects/records may have many instances re(use) the same structure. By using the record extension, this distinction is preserved in MessagePack and the encoding can reuse structures and not only provides better type preservation, but yield much more compact encodings and increase decoding performance by 2-3x. Msgpackr automatically generates record definitions that are reused and referenced by objects with the same structure. There are a number of ways to use this to our advantage. For large object structures with repeating nested objects with similar structures, simply serializing with the record extension can yield significant benefits. To use the record structures extension, we create a new Packr instance. By default a new Packr instance will have the record extension enabled:
Another way to further leverage the benefits of the msgpackr record structures is to use streams that naturally allow for data to reuse based on previous record structures. The stream classes have the record structure extension enabled by default and provide excellent out-of-the-box performance.
When creating a new Packr, Unpackr, PackrStream, or UnpackrStream instance, we can enable or disable the record structure extension with the useRecords property. When this is false, the record structure extension will be disabled (standard/compatibility mode), and all objects will revert to being serialized using MessageMap maps, and all maps will be deserialized to JS Objects as properties (like the standalone pack and unpack functions).
Streaming with record structures works by encoding a structure the first time it is seen in a stream and referencing the structure in later messages that are sent across that stream. When an encoder can expect a decoder to understand previous structure references, this can be configured using the sequential: true flag, which is auto-enabled by streams, but can also be used with Packr instances.
Shared Record Structures
Another useful way of using msgpackr, and the record extension, is for storing data in a databases, files, or other storage systems. If a number of objects with common data structures are being stored, a shared structure can be used to greatly improve data storage and deserialization efficiency. In the simplest form, provide a structures array, which is updated if any new object structure is encountered:
If you are working with persisted data, you will need to persist the structures data when it is updated. Msgpackr provides an API for loading and saving the structures on demand (which is robust and can be used in multiple-process situations where other processes may be updating this same structures array), we just need to provide a way to store the generated shared structure so it is available to deserialize stored data in the future:
import{Packr}from'msgpackr';letpackr=newPackr({getStructures(){// storing our data in file (but we could also store in a db or key-value store)returnunpack(readFileSync('my-shared-structures.mp'))||[];},saveStructures(structures){writeFileSync('my-shared-structures.mp',pack(structures));}});
Msgpackr will automatically add and saves structures as it encounters any new object structures (up to a limit of 32, by default). It will always add structures in an incremental/compatible way: Any object encoded with an earlier structure can be decoded with a later version (as long as it is persisted).
Shared Structures Options
By default there is a limit of 32 shared structures. This default is designed to record common shared structures, but also be resilient against sharing too many structures if there are many objects with dynamic properties that are likely to be repeated. This also allows for slightly more efficient one byte encoding. However, if your application has more structures that are commonly repeated, you can increase this limit by setting maxSharedStructures to a higher value. The maximum supported shared structures is 8160.
You can also provide a shouldShareStructure function in the options if you want to specifically indicate which structures should be shared. This is called during the encoding process with the array of keys for a structure that is being considered for addition to the shared structure. For example, you might want:
maxSharedStructures: 100,
shouldShareStructure(keys) {
return !(keys[0] > 1) // don't share structures that consist of numbers as keys
}
Reading Multiple Values
If you have a buffer with multiple values sequentially encoded, you can choose to parse and read multiple values. This can be done using the unpackMultiple function/method, which can return an array of all the values it can sequentially parse within the provided buffer. For example:
letdata=newUint8Array([1,2,3])// encodings of values 1, 2, and 3letvalues=unpackMultiple(data)// [1, 2, 3]
Alternately, you can provide a callback function that is called as the parsing occurs with each value, and can optionally terminate the parsing by returning false:
letdata=newUint8Array([1,2,3])// encodings of values 1, 2, and 3unpackMultiple(data,(value)=>{// called for each value// return false if you wish to end the parsing})
Options
The following options properties can be provided to the Packr or Unpackr constructor:
useRecords - Setting this to false disables the record extension and stores JavaScript objects as MessagePack maps, and unpacks maps as JavaScript Objects, which ensures compatibilty with other decoders.
structures - Provides the array of structures that is to be used for record extension, if you want the structures saved and used again. This array will be modified in place with new record structures that are serialized (if less than 32 structures are in the array).
moreTypes - Enable serialization of additional built-in types/classes including typed arrays, Sets, Maps, and Errors.
structuredClone - This enables the structured cloning extensions that will encode object/cyclic references. moreTypes is enabled by default when this is enabled.
mapsAsObjects - If true, this will decode MessagePack maps and JS Objects with the map entries decoded to object properties. If false, maps are decoded as JavaScript Maps. This is disabled by default if useRecords is enabled (which allows Maps to be preserved), and is enabled by default if useRecords is disabled.
useFloat32 - This will enable msgpackr to encode non-integer numbers as float32. See next section for possible values.
variableMapSize - This will use varying map size definition (fixmap, map16, map32) based on the number of keys when encoding objects, which yields slightly more compact encodings (for small objects), but is typically 5-10% slower during encoding. This is necessary if you need to use objects with more than 65535 keys. This is only relevant when record extension is disabled.
bundleStrings - If true this uses a custom extension that bundles strings together, so that they can be decoded more quickly on browsers and Deno that do not have access to the NodeJS addon. This a custom extension, so both encoder and decoder need to support this. This can yield significant decoding performance increases on browsers (30%-50%).
copyBuffers - When decoding a MessagePack with binary data (Buffers are encoded as binary data), copy the buffer rather than providing a slice/view of the buffer. If you want your input data to be collected or modified while the decoded embedded buffer continues to live on, you can use this option (there is extra overhead to copying).
useTimestamp32 - Encode JS Dates in 32-bit format when possible by dropping the milliseconds. This is a more efficient encoding of dates. You can also cause dates to use 32-bit format by manually setting the milliseconds to zero (date.setMilliseconds(0)).
sequential - Encode structures in serialized data, and reference previously encoded structures with expectation that decoder will read the encoded structures in the same order as encoded, with unpackMultiple.
largeBigIntToFloat - If a bigint needs to be encoded that is larger than will fit in 64-bit integers, it will be encoded as a float-64 (otherwise will throw a RangeError).
encodeUndefinedAsNil - Encodes a value of undefined as a MessagePack nil, the same as a null.
int64AsType - This will decode uint64 and int64 numbers as the specified type. The type can be bigint (default), number, or string.
onInvalidDate - This can be provided as function that will be called when an invalid date is provided. The function can throw an error, or return a value that will be encoded in place of the invalid date. If not provided, an invalid date will be encoded as an invalid timestamp (which decodes with msgpackr back to an invalid date).
32-bit Float Options
By default all non-integer numbers are serialized as 64-bit float (double). This is fast, and ensures maximum precision. However, often real-world data doesn't not need 64-bits of precision, and using 32-bit encoding can be much more space efficient. There are several options that provide more efficient encodings. Using the decimal rounding options for encoding and decoding provides lossless storage of common decimal representations like 7.99, in more efficient 32-bit format (rather than 64-bit). The useFloat32 property has several possible options, available from the module as constants:
ALWAYS (1) - Always will encode non-integers (absolute less than 2147483648) as 32-bit float.
DECIMAL_ROUND (3) - Always will encode non-integers as 32-bit float, and when decoding 32-bit float, round to the significant decimal digits (usually 7, but 6 or 8 digits for some ranges).
DECIMAL_FIT (4) - Only encode non-integers as 32-bit float if all significant digits (usually up to 7) can be unambiguously encoded as a 32-bit float, and decode/unpack with decimal rounding (same as above). This will ensure round-trip encoding/decoding without loss in precision and uses 32-bit when possible.
Note, that the performance is decreased with decimal rounding by about 20-25%, although if only 5% of your values are floating point, that will only have about a 1% impact overall.
In addition, msgpackr exports a roundFloat32(number) function that can be used to round floating point numbers to the maximum significant decimal digits that can be stored in 32-bit float, just as DECIMAL_ROUND does when decoding. This can be useful for determining how a number will be decoded prior to encoding it.
Performance
Native Acceleration
Msgpackr employs an optional native node-addon to accelerate the parsing of strings. This should be automatically installed and utilized on NodeJS. However, you can verify this by checking the isNativeAccelerationEnabled property that is exported from msgpackr. If this is false, the msgpackr-extract package may not have been properly installed, and you may want to verify that it is installed correctly:
import{isNativeAccelerationEnabled}from'msgpackr'if(!isNativeAccelerationEnabled)console.warn('Native acceleration not enabled, verify that install finished properly')
Benchmarks
Msgpackr is fast. Really fast. Here is comparison with the next fastest JS projects using the benchmark tool from msgpack-lite (and the sample data is from some clinical research data we use that has a good mix of different value types and structures). It also includes comparison to V8 native JSON functionality, and JavaScript Avro (avsc, a very optimized Avro implementation):
All benchmarks were performed on Node 15 / V8 8.6 (Windows i7-4770 3.4Ghz).
(avsc is schema-based and more comparable in style to msgpackr with shared structures).
Here is a benchmark of streaming data (again borrowed from msgpack-lite's benchmarking), where msgpackr is able to take advantage of the structured record extension and really demonstrate its performance capabilities:
operation (1000000 x 2)
op
ms
op/s
new PackrStream().write(obj);
1000000
372
2688172
new UnpackrStream().write(buf);
1000000
247
4048582
stream.write(msgpack.encode(obj));
1000000
2898
345065
stream.write(msgpack.decode(buf));
1000000
1969
507872
stream.write(notepack.encode(obj));
1000000
901
1109877
stream.write(notepack.decode(buf));
1000000
1012
988142
msgpack.Encoder().on("data",ondata).encode(obj);
1000000
1763
567214
msgpack.createDecodeStream().write(buf);
1000000
2222
450045
msgpack.createEncodeStream().write(obj);
1000000
1577
634115
msgpack.Decoder().on("data",ondata).decode(buf);
1000000
2246
445235
See the benchmark.md for more benchmarks and information about benchmarking.
Custom Extensions
You can add your own custom extensions, which can be used to encode specific types/classes in certain ways. This is done by using the addExtension function, and specifying the class, extension type code (should be a number from 1-100, reserving negatives for MessagePack, 101-127 for msgpackr), and your pack and unpack functions (or just the one you need).
import{addExtension,Packr}from'msgpackr';classMyCustomClass{...}letextPackr=newPackr();addExtension({Class: MyCustomClass,type: 11,// register your own extension code (a type code from 1-100)pack(instance){// define how your custom class should be encodedreturnBuffer.from([instance.myData]);// return a buffer}unpack(buffer){// define how your custom class should be decodedletinstance=newMyCustomClass();instance.myData=buffer[0];returninstance;// decoded value from buffer}});
If you want to use msgpackr to encode and decode the data within your extensions, you can use the read and write functions and read and write data/objects that will be encoded and decoded by msgpackr, which can be easier and faster than creating and receiving separate buffers:
import{addExtension,Packr}from'msgpackr';classMyCustomClass{...}letextPackr=newPackr();addExtension({Class: MyCustomClass,type: 11,// register your own extension code (a type code from 1-100)write(instance){// define how your custom class should be encodedreturninstance.myData;// return some data to be encoded}read(data){// define how your custom class should be decoded,// data will already be unpacked/decodedletinstance=newMyCustomClass();instance.myData=data;returninstance;// return decoded value}});
Note that you can just return the same object from write, and in this case msgpackr will encode it using the default object/array encoding:
You can also create an extension with Class and write methods, but no type (or read), if you just want to customize how a class is serialized without using MessagePack extension encoding.
Additional Performance Optimizations
Msgpackr is already fast, but here are some tips for making it faster:
Buffer Reuse
Msgpackr is designed to work well with reusable buffers. Allocating new buffers can be relatively expensive, so if you have Node addons, it can be much faster to reuse buffers and use memcpy to copy data into existing buffers. Then msgpackr unpack can be executed on the same buffer, with new data, and optionally take a second paramter indicating the effective size of the available data in the buffer.
Arena Allocation (useBuffer())
During the serialization process, data is written to buffers. Again, allocating new buffers is a relatively expensive process, and the useBuffer method can help allow reuse of buffers that will further improve performance. With useBuffer method, you can provide a buffer, serialize data into it, and when it is known that you are done using that buffer, you can call useBuffer again to reuse it. The use of useBuffer is never required, buffers will still be handled and cleaned up through GC if not used, it just provides a small performance boost.
Record Structure Extension Definition
The record struction extension uses extension id 0x72 ("r") to declare the use of this functionality. The extension "data" byte (or bytes) identifies the byte or bytes used to identify the start of a record in the subsequent MessagePack block or stream. The identifier byte (or the first byte in a sequence) must be from 0x40 - 0x7f (and therefore replaces one byte representations of positive integers 64 - 127, which can alternately be represented with int or uint types). The extension declaration must be immediately follow by an MessagePack array that defines the field names of the record structure.
Once a record identifier and record field names have been defined, the parser/decoder should proceed to read the next value. Any subsequent use of the record identifier as a value in the block or stream should parsed as a record instance, and the next n values, where is n is the number of fields (as defined in the array of field names), should be read as the values of the fields. For example, here we have defined a structure with fields "foo" and "bar", with the record identifier 0x40, and then read a record instance that defines the field values of 4 and 2, respectively:
Which should generate an object that would correspond to JSON:
{"foo": 4,"bar": 2}
Additional value types
msgpackr supports undefined (using fixext1 + type: 0 + data: 0 to match other JS implementations), NaN, Infinity, and -Infinity (using standard IEEE 754 representations with doubles/floats).
Dates
msgpackr saves all JavaScript Dates using the standard MessagePack date extension (type -1), using the smallest of 32-bit, 64-bit or 96-bit format needed to store the date without data loss (or using 32-bit if useTimestamp32 options is specified).
Structured Cloning
With structured cloning enabled, msgpackr will also use extensions to store Set, Map, Error, RegExp, ArrayBufferView objects and preserve their types.
Alternate Encoding/Package
The high-performance serialization and deserialization algorithms in the msgpackr package are also available in the cbor-x for the CBOR format, with the same API and design. A quick summary of the pros and cons of using MessagePack vs CBOR are:
MessagePack has wider adoption, and, at least with this implementation is slightly more efficient (by roughly 1%).
MessagePack can be a great choice for high-performance data delivery to browsers, as reasonable data size is possible without compression. And msgpackr works very well in modern browsers. However, it is worth noting that if you want highly compact data, brotli or gzip are most effective in compressing, and MessagePack's character frequency tends to defeat Huffman encoding used by these standard compression algorithms, resulting in less compact data than compressed JSON.
This library is a universal JavaScript, meaning it is compatible with all the major browsers and NodeJS. In addition, because it is implemented in TypeScript, type definition files (d.ts) are always up-to-date and bundled in the distribution.
Note that this is the second version of MessagePack for JavaScript. The first version, which was implemented in ES5 and was never released to npmjs.com, is tagged as classic.
It encodes data into a single MessagePack-encoded object, and returns a byte array as Uint8Array. It throws errors if data is, or includes, a non-serializable object such as a function or a symbol.
If you'd like to convert an uint8array to a NodeJS Buffer, use Buffer.from(arrayBuffer, offset, length) in order not to copy the underlying ArrayBuffer, while Buffer.from(uint8array) copies it:
import{encode}from"@msgpack/msgpack";constencoded: Uint8Array=encode({foo: "bar"});// `buffer` refers the same ArrayBuffer as `encoded`.constbuffer: Buffer=Buffer.from(encoded.buffer,encoded.byteOffset,encoded.byteLength);console.log(buffer);
It decodes buffer that includes a MessagePack-encoded object, and returns the decoded object typed unknown.
buffer must be an array of bytes, which is typically Uint8Array or ArrayBuffer. BufferSource is defined as ArrayBuffer | ArrayBufferView.
The buffer must include a single encoded object. If the buffer includes extra bytes after an object or the buffer is empty, it throws RangeError. To decode buffer that includes multiple encoded objects, use decodeMulti() or decodeMultiStream() (recommended) instead.
It decodes buffer that includes multiple MessagePack-encoded objects, and returns decoded objects as a generator. See also decodeMultiStream(), which is an asynchronous variant of this function.
This function is not recommended to decode a MessagePack binary via I/O stream including sockets because it's synchronous. Instead, decodeMultiStream() decodes a binary stream asynchronously, typically spending less CPU and memory.
It decodes stream, where ReadableStreamLike<T> is defined as ReadableStream<T> | AsyncIterable<T>, in an async iterable of byte arrays, and returns decoded object as unknown type, wrapped in Promise.
This function works asynchronously, and might CPU resources more efficiently compared with synchronous decode(), because it doesn't wait for the completion of downloading.
DecodeAsyncOptions is the same as DecodeOptions for decode().
This function is designed to work with whatwg fetch() like this:
import{decodeAsync}from"@msgpack/msgpack";constMSGPACK_TYPE="application/x-msgpack";constresponse=awaitfetch(url);constcontentType=response.headers.get("Content-Type");if(contentType&&contentType.startsWith(MSGPACK_TYPE)&&response.body!=null){constobject=awaitdecodeAsync(response.body);// do something with object}else{/* handle errors */}
It is alike to decodeAsync(), but only accepts a stream that includes an array of items, and emits a decoded item one by one.
for example:
import{decodeArrayStream}from"@msgpack/msgpack";conststream: AsyncIterator<Uint8Array>;// in an async function:forawait(constitemofdecodeArrayStream(stream)){console.log(item);}
It is alike to decodeAsync() and decodeArrayStream(), but the input stream must consist of multiple MessagePack-encoded items. This is an asynchronous variant for decodeMulti().
In other words, it could decode an unlimited stream and emits a decoded item one by one.
for example:
import{decodeMultiStream}from"@msgpack/msgpack";conststream: AsyncIterator<Uint8Array>;// in an async function:forawait(constitemofdecodeMultiStream(stream)){console.log(item);}
This function is available since v2.4.0; previously it was called as decodeStream().
Reusing Encoder and Decoder instances
Encoder and Decoder classes is provided to have better performance by reusing instances:
According to our benchmark, reusing Encoder instance is about 20% faster
than encode() function, and reusing Decoder instance is about 2% faster
than decode() function. Note that the result should vary in environments
and data structure.
This is an example to setup custom extension types that handles Map and Set classes in TypeScript:
import{encode,decode,ExtensionCodec}from"@msgpack/msgpack";constextensionCodec=newExtensionCodec();// Set<T>constSET_EXT_TYPE=0// Any in 0-127extensionCodec.register({type: SET_EXT_TYPE,encode: (object: unknown): Uint8Array|null=>{if(objectinstanceofSet){returnencode([...object]);}else{returnnull;}},decode: (data: Uint8Array)=>{constarray=decode(data)asArray<unknown>;returnnewSet(array);},});// Map<T>constMAP_EXT_TYPE=1;// Any in 0-127extensionCodec.register({type: MAP_EXT_TYPE,encode: (object: unknown): Uint8Array=>{if(objectinstanceofMap){returnencode([...object]);}else{returnnull;}},decode: (data: Uint8Array)=>{constarray=decode(data)asArray<[unknown,unknown]>;returnnewMap(array);},});constencoded=encode([newSet<any>(),newMap<any,any>()],{ extensionCodec });constdecoded=decode(encoded,{ extensionCodec });
Not that extension types for custom objects must be [0, 127], while [-1, -128] is reserved for MessagePack itself.
ExtensionCodec context
When you use an extension codec, it might be necessary to have encoding/decoding state to keep track of which objects got encoded/re-created. To do this, pass a context to the EncodeOptions and DecodeOptions:
import{encode,decode,ExtensionCodec}from"@msgpack/msgpack";classMyContext{track(object: any){/*...*/}}classMyType{/* ... */}constextensionCodec=newExtensionCodec<MyContext>();// MyTypeconstMYTYPE_EXT_TYPE=0// Any in 0-127extensionCodec.register({type: MYTYPE_EXT_TYPE,encode: (object,context)=>{if(objectinstanceofMyType){context.track(object);// <-- like thisreturnencode(object.toJSON(),{ extensionCodec, context });}else{returnnull;}},decode: (data,extType,context)=>{constdecoded=decode(data,{ extensionCodec, context });constmy=newMyType(decoded);context.track(my);// <-- and like thisreturnmy;},});// and laterimport{encode,decode}from"@msgpack/msgpack";constcontext=newMyContext();constencoded==encode({myType: newMyType<any>()},{ extensionCodec, context });constdecoded=decode(encoded,{ extensionCodec, context });
Handling BigInt with ExtensionCodec
This library does not handle BigInt by default, but you can handle it with ExtensionCodec like this:
import{deepStrictEqual}from"assert";import{encode,decode,ExtensionCodec}from"@msgpack/msgpack";constBIGINT_EXT_TYPE=0;// Any in 0-127constextensionCodec=newExtensionCodec();extensionCodec.register({type: BIGINT_EXT_TYPE,encode: (input: unknown)=>{if(typeofinput==="bigint"){if(input<=Number.MAX_SAFE_INTEGER&&input>=Number.MIN_SAFE_INTEGER){returnencode(parseInt(input.toString(),10));}else{returnencode(input.toString());}}else{returnnull;}},decode: (data: Uint8Array)=>{returnBigInt(decode(data));},});constvalue=BigInt(Number.MAX_SAFE_INTEGER)+BigInt(1);constencoded: =encode(value,{ extensionCodec });deepStrictEqual(decode(encoded,{ extensionCodec }),value);
The temporal module as timestamp extensions
There is a proposal for a new date/time representations in JavaScript:
This library maps Date to the MessagePack timestamp extension by default, but you can re-map the temporal module (or Temporal Polyfill) to the timestamp extension like this:
This will become default in this library with major-version increment, if the temporal module is standardized.
Decoding a Blob
Blob is a binary data container provided by browsers. To read its contents, you can use Blob#arrayBuffer() or Blob#stream(). Blob#stream()
is recommended if your target platform support it. This is because streaming
decode should be faster for large objects. In both ways, you need to use
asynchronous API.
asyncfunctiondecodeFromBlob(blob: Blob): unknown{if(blob.stream){// Blob#stream(): ReadableStream<Uint8Array> (recommended)returnawaitdecodeAsync(blob.stream());}else{// Blob#arrayBuffer(): Promise<ArrayBuffer> (if stream() is not available)returndecode(awaitblob.arrayBuffer());}}
MessagePack Specification
This library is compatible with the "August 2017" revision of MessagePack specification at the point where timestamp ext was added:
Note that as of June 2019 there're no official "version" on the MessagePack specification. See msgpack/msgpack#195 for the discussions.
MessagePack Mapping Table
The following table shows how JavaScript values are mapped to MessagePack formats and vice versa.
Source Value
MessagePack Format
Value Decoded
null, undefined
nil
null (*1)
boolean (true, false)
bool family
boolean (true, false)
number (53-bit int)
int family
number (53-bit int)
number (64-bit float)
float family
number (64-bit float)
string
str family
string
ArrayBufferView
bin family
Uint8Array (*2)
Array
array family
Array
Object
map family
Object (*3)
Date
timestamp ext family
Date (*4)
*1 Both null and undefined are mapped to nil (0xC0) type, and are decoded into null
*2 Any ArrayBufferViews including NodeJS's Buffer are mapped to bin family, and are decoded into Uint8Array
*3 In handling Object, it is regarded as Record<string, unknown> in terms of TypeScript
*4 MessagePack timestamps may have nanoseconds, which will lost when it is decoded into JavaScript Date. This behavior can be overridden by registering -1 for the extension codec.
Prerequisites
This is a universal JavaScript library that supports major browsers and NodeJS.
ECMA-262
ES5 language features
ES2018 standard library, including:
Typed arrays (ES2015)
Async iterations (ES2018)
Features added in ES2015-ES2018
ES2018 standard library used in this library can be polyfilled with core-js.
If you support IE11, import core-js in your application entrypoints, as this library does in testing for browsers.
NodeJS before v10 will work by importing @msgpack/msgpack/dist.es5+umd/msgpack.
TypeScript Compiler / Type Definitions
This module requires type definitions of AsyncIterator, SourceBuffer, whatwg streams, and so on. They are provided by "lib": ["ES2021", "DOM"] in tsconfig.json.
Regarding the TypeScript compiler version, only the latest TypeScript is tested in development.
Benchmark
Run-time performance is not the only reason to use MessagePack, but it's important to choose MessagePack libraries, so a benchmark suite is provided to monitor the performance of this library.
V8's built-in JSON has been improved for years, esp. JSON.parse() is significantly improved in V8/7.6, it is the fastest deserializer as of 2019, as the benchmark result bellow suggests.
However, MessagePack can handles binary data effectively, actual performance depends on situations. You'd better take benchmark on your own use-case if performance matters.
Benchmark on NodeJS/v18.1.0 (V8/10.1)
operation
op
ms
op/s
buf = Buffer.from(JSON.stringify(obj));
902100
5000
180420
obj = JSON.parse(buf.toString("utf-8"));
898700
5000
179740
buf = require("msgpack-lite").encode(obj);
411000
5000
82200
obj = require("msgpack-lite").decode(buf);
246200
5001
49230
buf = require("@msgpack/msgpack").encode(obj);
843300
5000
168660
obj = require("@msgpack/msgpack").decode(buf);
489300
5000
97860
buf = /* @msgpack/msgpack */ encoder.encode(obj);
1154200
5000
230840
obj = /* @msgpack/msgpack */ decoder.decode(buf);
448900
5000
89780
Note that JSON cases use Buffer to emulate I/O where a JavaScript string must be converted into a byte array encoded in UTF-8, whereas MessagePack modules deal with byte arrays.
Distribution
NPM / npmjs.com
The NPM package distributed in npmjs.com includes both ES2015+ and ES5 files:
dist/ is compiled into ES2019 with CommomJS, provided for NodeJS v10
dist.es5+umd/ is compiled into ES5 with UMD
dist.es5+umd/msgpack.min.js - the minified file
dist.es5+umd/msgpack.js - the non-minified file
dist.es5+esm/ is compiled into ES5 with ES modules, provided for webpack-like bundlers and NodeJS's ESM-mode
If you use NodeJS and/or webpack, their module resolvers use the suitable one automatically.
# run tests on NodeJS, Chrome, and Firefoxmake test-all
# edit the changelogcode CHANGELOG.md
# bump versionnpm version patch|minor|major
# run the publishing taskmake publish
this feature isn't in MessagePack spec but added as a convenience feature in 1.1.3
dictionaries allow us to decrease our buffer output size by recognizing strings used as object keys and replacing them with shorter-byte integer values during the encoding process
these shorter-byte placeholder values are then restored to their respective strings during the decoding process
the trade-off in using dictionaries is an insignificantly slower encoding and decoding time in exchange of a significantly smaller buffer output, which results into a lower network bandwidth and storage consumption in the long run
the best part: the byte placeholders starts from -32 then increments upwards, values -32 to 127 are encoded in single byte, which means your first (32 + 128) = 160 keys will be encoded as a single byte instead of encoding the whole string
constWebSocket=require('ws');constMessagePack=require('what-the-pack');const{ encode, decode }=MessagePack.initialize(2**22);// 4MBconstwss=newWebSocket.Server(/- options go here */);wss.on('connection',(client,req)=>{console.log('A client has connected.');console.log('IP address:',req.connection.remoteAddress);client.send(encode({message: 'something'}));});
client
On browsers, Buffer object is exposed as MessagePack.Buffer
On browsers, call MessagePack.Buffer.from(x) on received ArrayBuffers
This is a Kotilin implementation of MessagePack serialization and deserialization built ontop of Moshi to take advantage of Moshi's type adapters and utilizes okio for reading and writing MessagePack bytes.
The library is intended to be consumed in a Kotlin project, and is not intended for Java use.
data classMessagePackWebsitePlug(varcompact:Boolean = true, varschema:Int = 0)
val moshiPack =MoshiPack()
val packed:BufferedSource= moshiPack.pack(MessagePackWebsitePlug())
println(packed.readByteString().hex())
This prints the MessagePack bytes as a hex string 82a7636f6d70616374c3a6736368656d6100
82 - Map with two entries
a7 - String of seven bytes
63 6f 6d 70 61 63 74 - UTF8 String "compact"
c3 - Boolean value true
a6 - String of size bytes
73 63 68 65 6d 61 - UTF8 String "schema"
00 - Integer value 0
Convert binary MessagePack back to an Object
val bytes =ByteString.decodeHex("82a7636f6d70616374c3a6736368656d6100").toByteArray()
val moshiPack =MoshiPack()
val plug:MessagePackWebsitePlug= moshiPack.unpack(bytes)
Static API
If you prefer to not instantiate a MoshiPack instance you can access the API in a static fashion as well. Note this will create a new Moshi instance every time you make an API call. You may want to use the API this way if you aren't providing MoshiPack by some form of dependency injection and you do not have any specific builder parameters for Moshi
Serializes an object into MessagePack. Returns:okio.BufferedSource
Instance version:
MoshiPack().pack(anyObject)
Static version:
MoshiPack.pack(anyObject)
packToByeArray
If you prefer to get a ByteArray instead of a BufferedSource you can use this method.
Instance version only
MoshiPack().packToByteArray(anObject)
Static can be done
MoshiPack.pack(anObject).readByteArray()
unpack
Deserializes MessagePack bytes into an Object. Returns:T: Any
Works with ByteArray and okio.BufferedSource
Instance version:
// T must be valid type so Moshi knows what to deserialize toval unpacked:T=MoshiPack().unpack(byteArray)
Static version:
val unpacked:T=MoshiPack.upack(byteArray)
Instance version:
val unpacked:T=MoshiPack().unpack(bufferedSource)
Static version:
val unpacked:T=MoshiPack.upack(bufferedSource)
T can be an Object, a List, a Map, and can include generics. Unlike Moshi you do not need to specify a parameterized type to deserialize to a List with generics. MoshiPack can infer the paramterized type for you.
The following examples are valid for MoshiPack:
A typed List
val listCars:List<Car> =MoshiPack.unpack(carMsgPkBytes)
A List of Any
val listCars:List<Any> =MoshiPack.unpack(carMsgPkBytes)
An Object
val car:Car=MoshiPack.unpack(carBytes)
A Map of Any, Any
val car:Map<Any, Any> =MoshiPack.unpack(carBytes)
msgpackToJson
Convert directly from MessagePack bytes to JSON. Use this method for the most effecient implementation as no objects are instantiated in the process. This uses the FormatInterchange class to match implementations of JsonReader and a JsonWriter. If you wanted to say support XML as a direct conversion to and from, you could implement Moshi's JsonReader and JsonWriter classes and use the FormatInterchange class to convert directly to other formats. ReturnsString containing a JSON representation of the MessagePack data
Instance versions: (takes ByteArray or BufferedSource)
MoshiPack().msgpackToJson(byteArray)
MoshiPack().msgpackToJson(bufferedSource)
Static versions: (takes ByteArray or BufferedSource)
MoshiPack.msgpackToJson(byteArray)
MoshiPack.msgpackToJson(bufferedSource)
jsonToMsgpack
Convert directly from JSON to MessagePack bytes. Use this method for the most effecient implementation as no objects are instantiated in the process. ReturnsBufferedSource
Instance versions: (takes String or BufferedSource)
MoshiPack().jsonToMsgpack(jsonString)
MoshiPack().jsonToMsgpack(bufferedSource)
Static versions: (takes String or BufferedSource)
MoshiPack.jsonToMsgpack(jsonString)
MoshiPack.jsonToMsgpack(bufferedSource)
MoshiPack - constructor + Moshi builder
The MoshiPack constructor takes an optional Moshi.Builder.() -> Unit lambda which is applied to the builder that is used to instantiate the Moshi instance it uses.
Example adding custom adapter:
val moshiPack =MoshiPack({
add(customAdapter)
})
Moshi is also a settable property which can be changed on a MoshiPack instance:
val m =MoshiPack()
m.moshi =Moshi.Builder().build()
The static version of the API also can be passed a lambda to applied to the Moshi.Builder used to instantiate Moshi:
MoshiPack.pack(someBytes) { add(customAdapter) }
Forcing integers to write as certain format
new in v1.0.1
This will force all integers to be packed as the type given.
By default the smallest message pack type is used for integers.
val moshiPack =MoshiPack().apply {
writerOptions.writeAllIntsAs =MsgpackIntByte.INT_64
}
Kotiln Support
Since this library is intended for Kotlin use, the moshi-kotlin artifact is included as a depedency. A KotlinJsonAdapterFactory is added by default to the instantiated Moshi that MoshiPack uses.
This adapter allows for the use of Moshi's annotaions in Kotlin. To learn more about it see the Moshi documentation.
If you'd like to use Moshi with out a KotlinJsonAdapterFactory supply a Moshi instance for MoshiPack:
MoshiPack(moshi =Moshi.Builder().build)
ProGuard
From Moshi's README.md;
If you are using ProGuard you might need to add the following options:
-dontwarn okio.**
-dontwarn javax.annotation.**
-keepclasseswithmembers class * {
@com.squareup.moshi.* <methods>;
}
-keep @com.squareup.moshi.JsonQualifier interface *
-keepclassmembers class kotlin.Metadata {
public <methods>;
}
local msgpack =require('msgpack')
local value = msgpack.decode(binary_msgpack_data) -- decode to Lua valuelocal binary_data = msgpack.encode(lua_value) -- encode Lua value to MessagePack
API
msgpack.encode_one(value)
Encodes the given Lua value to a binary MessagePack representation. It will return the binary string on succes or nil plus an error message if it fails.
The encoder will encode Lua strings as MessagePack strings when they are properly UTF-8 encoded otherwise they will become MessagePack binary objects.
There is also a check if a Lua number can be lossless encoded as a 32-bit float.
NOTE: Empty Lua tables will be encoded as empty arrays!
msgpack.encode(...)
Encodes all given values to a binary MessagePack representation. It will return the binary string or nil plus an error message if it fails.
Decode the given MessagePack binary string to a corresponding Lua value. It will return the decoded Lua value and the position for next byte in stream
or nil plus an error message if decoding went wrong. You can use the returned position to decode multiple MessagePack values in a stream.
The optional position argument is used to start the decoding at a specific position inside the the binary_data string.
NOTE: Extended types are not supported. Decoding will fail!
NOTE: Binary data will be decoded as Lua strings
NOTE: Arrays will be decoded as Lua tables starting with index 1 (like Lua uses tables as arrays)
NOTE: Values which are nil will cause the key, value pair to disappear in a Lua table (that's how it works in Lua)
msgpack.decode(binary_data[, position])
Decode the given MessagePack binary string to one or more Lua values. It will return all decoded Lua values or nil plus an error message if decoding failed.
local a, b, c = msgpack.decode(binary)
License
This is free and unencumbered software released into the public domain.
Anyone is free to copy, modify, publish, use, compile, sell, or
distribute this software, either in source code form or as a compiled
binary, for any purpose, commercial or non-commercial, and by any
means.
In jurisdictions that recognize copyright laws, the author or authors
of this software dedicate any and all copyright interest in the
software to the public domain. We make this dedication for the benefit
of the public at large and to the detriment of our heirs and
successors. We intend this dedication to be an overt act of
relinquishment in perpetuity of all present and future rights to this
software under copyright law.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR
OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
OTHER DEALINGS IN THE SOFTWARE.
For more information, please refer to <http://unlicense.org/>
A MessagePack implementation for Matlab and Octave
The code is written in pure Matlab, and has no dependencies beyond Matlab itself. And it works in recent versions of Octave, too.
The files in this repository are taken from Transplant.
Basic Usage:
data = {'life, the universe, and everything', struct('the_answer', 42)};
bytes =dumpmsgpack(data)
data =parsemsgpack(bytes)
% returns: {'life, the universe, and everything', containers.Map('the_answer', 42)}
Converting Matlab to MsgPack:
Matlab
MsgPack
string
string
scalar
number
logical
true/false
vector
array of numbers
uint8 vector
bin
matrix
array of array of numbers
empty matrix
nil
cell array
array
cell matrix
array of arrays
struct
map
containers.Map
map
struct array
array of maps
handles
raise error
There is no way of encoding exts
Converting MsgPack to Matlab
MsgPack
Matlab
string
string
number
scalar
true/false
logical
nil
empty matrix
array
cell array
map
containers.Map
bin
uint8
ext
uint8
Note that since structs don't support arbitrary field names, they can't be used for representing maps. We use containers.Map instead.
Tests
runtests()
License
MATLAB (R) is copyright of the Mathworks
Copyright (c) 2014 Bastian Bechtold
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are
met:
Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the
distribution.
Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived
from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
msgpack-nim currently provides only the basic functionality.
Please see what's listed in Todo section. Compared to other language bindings, it's well-tested by
1000 auto-generated test cases by Haskell QuickCheck, which always runs
on every commit to Github repository. Please try make quickcheck on your local machine
to see what happens (It will take a bit while. Be patient). Have a nice packing!
Install
$ nimble update
$ nimble install msgpack
Example
import msgpack
import streams
# You can use any stream subclasses to serialize/deserialize# messages. e.g. FileStreamlet st: Stream = newStringStream()
assert(st.getPosition == 0)
# Type checking protects you from making trivial mistakes.# Now we pack {"a":[5,-3], "b":[1,2,3]} but more complex# combination of any Msg types is allowed.## In xs we can mix specific conversion (PFixNum) and generic# conversion (unwrap).let xs: Msg = wrap(@[PFixNum(5), (-3).wrap])
let ys: Msg = wrap(@[("a".wrap, xs.wrap), ("b".wrap, @[1, 2, 3].wrap)])
st.pack(ys.wrap) # Serialize!# We need to reset the cursor to the beginning of the target# byte sequence.
st.setPosition(0)
let msg = st.unpack # Deserialize!# output:# a# 5# -3# b# 1# 2# 3for e in msg.unwrapMap:
echo e.key.unwrapStr
for e in e.val.unwrapArray:
echo e.unwrapInt
Todo
Implement unwrapInto to convert Msg object to Nim object handily
Evaluate performance and scalability
Talk with offical Ruby implementation
Don't repeat yourself: The code now has too much duplications. Using templates?
I am fully aware of another msgpack implementation written in nim.
But I want something easier to use. Another motivation come from the nim language itself.
The current version of nim compiler offer many improvements, including 'generics ' specialization.
I found out nim compiler is smart enough to make serialization/deserialization to/from msgpack easy and convenient.
requirement: nim ver 0.18.1 or later
Example
import msgpack4nim, streams
type#lets try with a rather complex objectCustomType = object
count: int
content: seq[int]
name: string
ratio: float
attr: array[0..5, int]
ok: boolprocinitCustomType():CustomType=
result.count = -1
result.content = @[1,2,3]
result.name = "custom"
result.ratio = 1.0for i in0..5: result.attr[i] = i
result.ok = falsevar x = initCustomType()
var s = MsgStream.init() # besides MsgStream, you can also use Nim StringStream or FileStream
s.pack(x) #here the magic happenedvar ss = MsgStream.init(s.data)
var xx: CustomType
ss.unpack(xx) #and here tooassert xx == x
echo"OK ", xx.name
see? you only need to call 'pack' and 'unpack', and the compiler do the hard work for you. Very easy, convenient, and works well
if you think setting up a MsgStream too much for you, you can simply call pack(yourobject) and it will return a string containing msgpack data.
var a = @[1,2,3,4,5,6,7,8,9,0]
var buf = pack(a)
var aa: seq[int]
unpack(buf, aa)
assert a == aa
in case the compiler cannot decide how to serialize or deserialize your very very complex object, you can help it in easy way
by defining your own handler pack_type/unpack_type
type#not really complex, just for example
mycomplexobject = object
a: someSimpleType
b: someSimpleType
# help the compiler to decide# ByteStream is any Stream Compatible object such as MsgStream, FileStream, StringStreamprocpack_type*[ByteStream](s: ByteStream, x: mycomplexobject) =
s.pack(x.a) # let the compiler decide
s.pack(x.b) # let the compiler decide# help the compiler to decide# ByteStream is any Stream Compatible objectprocunpack_type*[ByteStream](s: ByteStream, x: var mycomplexobject) =
s.unpack(x.a)
s.unpack(x.b)
var s = MsgStream.init() # besides MsgStream, you can also use Nim StringStream or FileStreamvar x: mycomplexobject
s.pack(x) #pack as usualvar ss = MsgStream.init(s.data)
ss.unpack(x) #unpack as usual
(*) please import msgpakc4collection for Nim standard library collections, they are no longer part of codec core
(**) provide your own implementation if you want to override default behavior
distinct types
If distinct types encountered, it will be converted back to it's base type.
If you don't like this behavior, since version 0.2.9 msgpack4nim allow you
to override this default behavior by supplying your own implementation of
pack_type and unpack_type.
import msgpack4nim, strutils
typeGuid = distinctstringprocpack_type*[ByteStream](s: ByteStream, v: Guid) =
s.pack_bin(len(v.string))
s.write(v.string)
procunpack_type*[ByteStream](s: ByteStream, v: varGuid) =let L = s.unpack_bin()
v = Guid(s.readStr(L))
var b = Guid("AA")
var s = b.pack
echo s.tohex == "C4024141"echo s.stringify == "BIN: 4141 "var bb: Guid
s.unpack(bb)
check bb.string == b.string
object and tuple
object and tuple by default converted to msgpack array, however
you can tell the compiler to convert it to map by supplying --define:msgpack_obj_to_map
nim c --define:msgpack_obj_to_map yourfile.nim
or --define:msgpack_obj_to_stream to convert object/tuple fields value into stream of msgpack objects
nim c --define:msgpack_obj_to_stream yourfile.nim
What this means? It means by default, each object/tuple will be converted to one msgpack array contains
field(s) value only without their field(s) name.
If you specify that the object/tuple will be converted to msgpack map, then each object/tuple will be
converted to one msgpack map contains key-value pairs. The key will be field name, and the value will be field value.
If you specify that the object/tuple will be converted to msgpack stream, then each object/tuple will be converted
into one or more msgpack's type for each object's field and then the resulted stream will be concatenated
to the msgpack stream buffer.
Which one should I use?
Usually, other msgpack libraries out there convert object/tuple/record/struct or whatever structured data supported by
the language into msgpack array, but always make sure to consult the documentation first.
If both of the serializer and deserializer agreed to one convention, then usually there will be no problem.
No matter which library/language you use, you can exchange msgpack data among them.
since version 0.2.4, you can set encoding mode at runtime to choose which encoding you would like to perform
note: the runtime encoding mode only available if you use MsgStream, otherwise only compile time flag available
mode
msgpack_obj_to_map
msgpack_obj_to_array
msgpack_obj_to_stream
default
MSGPACK_OBJ_TO_DEFAULT
map
array
stream
array
MSGPACK_OBJ_TO_ARRAY
array
array
array
array
MSGPACK_OBJ_TO_MAP
map
map
map
map
MSGPACK_OBJ_TO_STREAM
stream
stream
stream
stream
ref-types:
ref something :
if ref value is nil, it will be packed into msgpack nil, and when unpacked, you will get nil too
if ref value not nil, it will be dereferenced e.g. pack(val[]) or unpack(val[])
ref subject to some restriction. see restriction below
ptr will be treated like ref during pack
unpacking ptr will invoke alloc, so you must dealloc it
circular reference:
altough detecting circular reference is not too difficult(using set of pointers),
the current implementation does not provide circular reference detection.
If you pack something contains circular reference, you know something bad will happened
Restriction:
For objects their type is not serialized.
This means essentially that it does not work if the object has some other runtime type than its compiletime type:
import streams, msgpack4nim
typeTA = objectofRootObjTB = objectofTA
f: intvar
a: refTA
b: refTBnew(b)
a = b
echostringify(pack(a))
#produces "[ ]" or "{ }"#not "[ 0 ]" or '{ "f" : 0 }'
limitation:
these types will be ignored:
procedural type
cstring(it is not safe to assume it always terminated by null)
pointer
these types cannot be automatically pack/unpacked:
void (will cause compile time error)
however, you can provide your own handler for cstring and pointer
Gotchas:
because data conversion did not preserve original data types(only partial preservation),
the following code is perfectly valid and will raise no exception
import msgpack4nim, streams, tables, sets, strtabs
typeHorse = object
legs: int
foals: seq[string]
attr: Table[string, string]
Cat = object
legs: uint8
kittens: HashSet[string]
traits: StringTableRefprocinitHorse():Horse=
result.legs = 4
result.foals = @["jilly", "colt"]
result.attr = initTable[string, string]()
result.attr["color"] ="black"
result.attr["speed"] ="120mph"var stallion = initHorse()
var tom: Catvar buf = pack(stallion) #pack a Horse hereunpack(buf, tom)
#abracadabra, it will unpack into a Catecho"legs: ", $tom.legs
echo"kittens: ", $tom.kittens
echo"traits: ", $tom.traits
another gotcha:
typeKAB = objectofRootObj
aaa: int
bbb: intKCD = objectofKAB
ccc: int
ddd: intKEF = objectofKCD
eee: int
fff: intvar kk = KEF()
echostringify(pack(kk))
# will produce "{ "eee" : 0, "fff" : 0, "ccc" : 0, "ddd" : 0, "aaa" : 0, "bbb" : 0 }"# not "{ "aaa" : 0, "bbb" : 0, "ccc" : 0, "ddd" : 0, "eee" : 0, "fff" : 0 }"
bin and ext format
this implementation provide function to encode/decode msgpack bin/ext format header,
but for the body, you must write it yourself or read it yourself to/from the MsgStream
import streams, msgpack4nim
const exttype0 = 0var s = MsgStream.init()
var body = "this is the body"
s.pack_ext(body.len, exttype0)
s.write(body)
#the same goes to bin format
s.pack_bin(body.len)
s.write(body)
var ss = MsgStream.init(s.data)
#unpack_ext return tuple[exttype:uint8, len: int]let (extype, extlen) = ss.unpack_ext()
var extbody = ss.readStr(extlen)
assert extbody == body
let binlen = ss.unpack_bin()
var binbody = ss.readStr(binlen)
assert binbody == body
stringify
you can convert msgpack data to readable string using stringify function
typeHorse = object
legs: int
speed: int
color: string
name: stringvar cc = Horse(legs:4, speed:150, color:"black", name:"stallion")
var zz = pack(cc)
echostringify(zz)
toAny takes a string of msgpack data or a stream, then it will produce msgAny
which you can interrogate of it's type and value during runtime by accessing it's member kind
toAny recognize all valid msgpack message and translate it into a group of types:
for example, msg is a msgpack data with content [1, "hello", {"a": "b"}], you can interrogate it like this:
var a = msg.toAny()
assert a.kind == msgArray
assert a.arrayVal[0].kind == msgInt
assert a.arrayVal[0].intVal == 1assert a.arrayVal[1].kind == msgString
assert a.arrayVal[1].stringVal == "hello"assert a.arrayVal[2].kind == msgMap
var c = a[2]
assert c[anyString("a")] ==anyString("b")
since version 0.2.1, toAny was put into separate module msgpack2any,
it has functionality similar with json, with support of msgpack bin and ext natively
msgpack2any also support pretty printing similar with json pretty printing.
Primary usage for msgpack2any is to provide higher level API while dynamically querying underlying msgpack data at runtime.
Currently, msgpack2any decode all msgpack stream at once. There are room for improvements such as progressive decoding at
runtime, or selective decoding at runtime. Both of this improvements are not implemented, yet they are important for applications
that need for finer control over decoding step.
JSON
Start version 0.2.0, msgpack4nim receive additional family member, msgpack2json module.
It consists of toJsonNode and fromJsonNode to interact with stdlib's json module.
Installation via nimble
nimble install msgpack4nim
Implementation specific
If an object can be represented in multiple possible output formats,
serializers SHOULD use the format which represents the data in the smallest number of bytes.
According to the spec, the serializer should use smallest number of bytes, and this behavior
is implemented in msgpack4nim. Therefore, some valid encoding would never produced by msgpack4nim.
For example: although 0xcdff00 and 0xceff000000 encoding is valid according to the spec which is decoded into positive integer 255,
msgpack4nim never produce it, because the internal algorithm will select the smallest number of bytes needed, which is 0xccff.
However, if msgpack4nim received encoded streams from other msgpack library contains those longer than needed sequence, as long as
it conforms to the spec, msgpack4nim will happily decoded it and convert it to the destination storage(variable) type.
Other msgpack library who consume msgpack4nim stream, will also decode it properly, although they might not produce smallest number
of bytes required.
Creates a new instance on which you can register new types for being
encoded.
options:
forceFloat64, a boolean to that forces all floats to be encoded as 64-bits floats. Defaults to false.
sortKeys, a boolean to force a determinate keys order
compatibilityMode, a boolean that enables "compatibility mode" which doesn't use bin format family and str 8 format. Defaults to false.
disableTimestampEncoding, a boolean that when set disables the encoding of Dates into the timestamp extension type. Defaults to false.
preferMap, a boolean that forces all maps to be decoded to Maps rather than plain objects. This ensures that decode(encode(new Map())) instanceof Map and that iteration order is preserved. Defaults to false.
protoAction, a string which can be error|ignore|remove that determines what happens when decoding a plain object with a __proto__ property which would cause prototype poisoning. error (default) throws an error, remove removes the property, ignore (not recommended) allows the property, thereby causing prototype poisoning on the decoded object.
Decodes buf from in msgpack. buf can be a Buffer or a bl instance.
In order to support a stream interface, a user must pass in a bl instance.
registerEncoder(check(obj), encode(obj))
Register a new custom object type for being automatically encoded.
The arguments are:
check, a function that will be called to check if the passed
object should be encoded with the encode function
encode, a function that will be called to encode an object in binary
form; this function must return a Buffer which include the same type
for registerDecoder.
registerDecoder(type, decode(buf))
Register a new custom object type for being automatically decoded.
The arguments are:
type, is a greater than zero integer identificating the type once serialized
decode, a function that will be called to decode the object from
the passed Buffer
Register a new custom object type for being automatically encoded and
decoded. The arguments are:
type, is a greater than zero integer identificating the type once serialized
constructor, the function that will be used to match the objects
with instanceof
encode, a function that will be called to encode an object in binary
form; this function must return a Buffer that can be
deserialized by the decode function
decode, a function that will be called to decode the object from
the passed Buffer
Automatic Message Pack detection (from the HTTP headers) and encoding of all JSON messages to Message Pack.
Extension of the current ExpressJS API; Introducing the Response.msgPack(jsObject) method on the standard ExpressJS Response object.
Getting Started
With auto-detection and transformation enabled, the middleware detects automatically the HTTP header Accept: application/x-msgpack and piggybacks the Response.json() method of the ExpressJS API, to encode the JSON response as Message Pack. This method is useful when you have existing applications that need to use the middleware, without changing the codebase very much.
constmsgpackResponse=require('msgpack-response');app.use(msgpackResponse({auto_detect: true}));app.get('/test_json',(req,res)=>{res.status(200).json({'message': 'a true test'});})
Note: Remember to add the header Accept: application/x-msgpack in the request.
Also, it can have auto-detection and transformation disabled. The middleware extends the Response object of the ExpressJS framework, by adding the msgPack() method to it. Then to return an encoded response, you just use the Response.msgPack() method that accepts the Javascript object as a parameter. For example,
constmsgpackResponse=require('msgpack-response');app.use(msgpackResponse({auto_detect: false}));//orapp.use(msgpackResponse());app.get('/test_msgpack',(req,res)=>{res.status(200).msgPack({'message': 'a true test'});});
Note: Initialize the middleware before the actual routes in the middleware chain to properly extend the Response Object.
This extension provides an API for communicating with MessagePack serialization.
MessagePack is a binary-based efficient object serialization library.
It enables to exchange structured objects between many languages just like JSON.
But unlike JSON, it is very fast and small.
Requirement
PHP 7.0 +
Install
Install from PECL
Msgpack is an PECL extension, thus you can simply install it by:
pecl install msgpack
Compile Msgpack from source
/path/to/phpize
./configure --with-php-config=/path/to/php-config
make && make install
In the examples above, the method pack automatically packs a value depending on its type. However, not all PHP types
can be uniquely translated to MessagePack types. For example, the MessagePack format defines map and array types,
which are represented by a single array type in PHP. By default, the packer will pack a PHP array as a MessagePack
array if it has sequential numeric keys, starting from 0 and as a MessagePack map otherwise:
Check the "Custom types" section below on how to pack custom types.
Packing options
The Packer object supports a number of bitmask-based options for fine-tuning
the packing process (defaults are in bold):
Name
Description
FORCE_STR
Forces PHP strings to be packed as MessagePack UTF-8 strings
FORCE_BIN
Forces PHP strings to be packed as MessagePack binary data
DETECT_STR_BIN
Detects MessagePack str/bin type automatically
FORCE_ARR
Forces PHP arrays to be packed as MessagePack arrays
FORCE_MAP
Forces PHP arrays to be packed as MessagePack maps
DETECT_ARR_MAP
Detects MessagePack array/map type automatically
FORCE_FLOAT32
Forces PHP floats to be packed as 32-bits MessagePack floats
FORCE_FLOAT64
Forces PHP floats to be packed as 64-bits MessagePack floats
The type detection mode (DETECT_STR_BIN/DETECT_ARR_MAP) adds some overhead
which can be noticed when you pack large (16- and 32-bit) arrays or strings.
However, if you know the value type in advance (for example, you only work with
UTF-8 strings or/and associative arrays), you can eliminate this overhead by
forcing the packer to use the appropriate type, which will save it from running
the auto-detection routine. Another option is to explicitly specify the value
type. The library provides 2 auxiliary classes for this, Map and Bin.
Check the "Custom types" section below for details.
Examples:
// detect str/bin type and pack PHP 64-bit floats (doubles) to MP 32-bit floats$packer = newPacker(PackOptions::DETECT_STR_BIN | PackOptions::FORCE_FLOAT32);
// these will throw MessagePack\Exception\InvalidOptionException$packer = newPacker(PackOptions::FORCE_STR | PackOptions::FORCE_BIN);
$packer = newPacker(PackOptions::FORCE_FLOAT32 | PackOptions::FORCE_FLOAT64);
Unpacking
To unpack data you can either use an instance of a BufferUnpacker:
If the packed data is received in chunks (e.g. when reading from a stream), use the tryUnpack method, which attempts
to unpack data and returns an array of unpacked messages (if any) instead of throwing an InsufficientDataException:
while ($chunk = ...) {
$unpacker->append($chunk);
if ($messages = $unpacker->tryUnpack()) {
return$messages;
}
}
If you want to unpack from a specific position in a buffer, use seek:
$unpacker->seek(42); // set position equal to 42 bytes$unpacker->seek(-8); // set position to 8 bytes before the end of the buffer
To skip bytes from the current position, use skip:
$unpacker->skip(10); // set position to 10 bytes ahead of the current position
To get the number of remaining (unread) bytes in the buffer:
The BufferUnpacker object supports a number of bitmask-based options for fine-tuning
the unpacking process (defaults are in bold):
Name
Description
BIGINT_AS_STR
Converts overflowed integers to strings [1]
BIGINT_AS_GMP
Converts overflowed integers to GMP objects [2]
BIGINT_AS_DEC
Converts overflowed integers to Decimal\Decimal objects [3]
1. The binary MessagePack format has unsigned 64-bit as its largest integer
data type, but PHP does not support such integers, which means that
an overflow can occur during unpacking.
In addition to the basic types, the library
provides functionality to serialize and deserialize arbitrary types. This can be done in several ways, depending
on your use case. Let's take a look at them.
Type objects
If you need to serialize an instance of one of your classes into one of the basic MessagePack types, the best way
to do this is to implement the CanBePacked interface in the class. A good example of such
a class is the Map type class that comes with the library. This type is useful when you want to explicitly specify
that a given PHP array should be packed as a MessagePack map without triggering an automatic type detection routine:
More type examples can be found in the src/Type directory.
Type transformers
As with type objects, type transformers are only responsible for serializing values. They should be
used when you need to serialize a value that does not implement the CanBePacked
interface. Examples of such values could be instances of built-in or third-party classes that you don't
own, or non-objects such as resources.
A transformer class must implement the CanPack interface. To use a transformer,
it must first be registered in the packer. Here is an example of how to serialize PHP streams into
the MessagePack bin format type using one of the supplied transformers, StreamTransformer:
More type transformer examples can be found in the src/TypeTransformer directory.
Extensions
In contrast to the cases described above, extensions are intended to handle
extension types
and are responsible for both serialization and deserialization of values (types).
An extension class must implement the Extension interface. To use an extension,
it must first be registered in the packer and the unpacker.
The MessagePack specification divides extension types into two groups: predefined and application-specific.
Currently, there is only one predefined type in the specification, Timestamp.
Timestamp
The Timestamp extension type is a predefined
type. Support for this type in the library is done through the TimestampExtension class. This class is responsible
for handling Timestamp objects, which represent the number of seconds and optional adjustment in nanoseconds:
In addition, the format can be extended with your own types. For example, to make the built-in PHP DateTime objects
first-class citizens in your code, you can create a corresponding extension, as shown in the example.
Please note, that custom extensions have to be registered with a unique extension ID (an integer from 0 to 127).
To learn more about how extension types can be useful, check out this
article.
Exceptions
If an error occurs during packing/unpacking, a PackingFailedException or an UnpackingFailedException
will be thrown, respectively. In addition, an InsufficientDataException can be thrown during unpacking.
An InvalidOptionException will be thrown in case an invalid option (or a combination of mutually
exclusive options) is used.
Tests
Run tests as follows:
vendor/bin/phpunit
Also, if you already have Docker installed, you can run the tests in a docker container. First, create a container:
./dockerfile.sh | docker build -t msgpack -
The command above will create a container named msgpack with PHP 8.1 runtime. You may change the default runtime
by defining the PHP_IMAGE environment variable:
docker run --rm -v $PWD:/msgpack -w /msgpack msgpack
Fuzzing
To ensure that the unpacking works correctly with malformed/semi-malformed data, you can use a testing technique
called Fuzzing. The library ships with a help file (target)
for PHP-Fuzzer and can be used as follows:
export MP_BENCH_TARGETS=pure_p
export MP_BENCH_ITERATIONS=1000000
export MP_BENCH_ROUNDS=5
# a comma separated list of test namesexport MP_BENCH_TESTS='complex array, complex map'# or a group name# export MP_BENCH_TESTS='-@slow' // @pecl_comp# or a regexp# export MP_BENCH_TESTS='/complex (array|map)/'
Another example, benchmarking both the library and the PECL extension:
use Data::MessagePack;
my $mp = Data::MessagePack->new();
$mp->canonical->utf8->prefer_integer if $needed;
my $packed = $mp->pack($dat);
my $unpacked = $mp->unpack($dat);
DESCRIPTION
This module converts Perl data structures to MessagePack and vice versa.
ABOUT MESSAGEPACK FORMAT
MessagePack is a binary-based efficient object serialization format.
It enables to exchange structured objects between many languages like
JSON. But unlike JSON, it is very fast and small.
ADVANTAGES
PORTABLE
The MessagePack format does not depend on language nor byte order.
SMALL IN SIZE
say length(JSON::XS::encode_json({a=>1, b=>2})); # => 13
say length(Storable::nfreeze({a=>1, b=>2})); # => 21
say length(Data::MessagePack->pack({a=>1, b=>2})); # => 7
The MessagePack format saves memory than JSON and Storable format.
STREAMING DESERIALIZER
MessagePack supports streaming deserializer. It is useful for
networking such as RPC. See Data::MessagePack::Unpacker for
details.
If you want to get more information about the MessagePack format,
please visit to http://msgpack.org/.
METHODS
my $packed = Data::MessagePack->pack($data[, $max_depth]);
Pack the $data to messagepack format string.
This method throws an exception when the perl structure is nested more
than $max_depth levels(default: 512) in order to detect circular
references.
Data::MessagePack->pack() throws an exception when encountering a
blessed perl object, because MessagePack is a language-independent
format.
my $unpacked = Data::MessagePack->unpack($msgpackstr);
unpack the $msgpackstr to a MessagePack format string.
my $mp = Data::MesssagePack->new()
Creates a new MessagePack instance.
$mp = $mp->prefer_integer([ $enable ])
$enabled = $mp->get_prefer_integer()
If $enable is true (or missing), then the pack method tries a
string as an integer if the string looks like an integer.
$mp = $mp->canonical([ $enable ])
$enabled = $mp->get_canonical()
If $enable is true (or missing), then the pack method will output
packed data by sorting their keys. This is adding a comparatively high
overhead.
$mp = $mp->utf8([ $enable ])
$enabled = $mp->get_utf8()
If $enable is true (or missing), then the pack method will
apply utf8::encode() to all the string values.
In other words, this property tell $mp to deal with text strings.
See perlunifaq for the meaning of text string.
$packed = $mp->pack($data)
$packed = $mp->encode($data)
Same as Data::MessagePack->pack(), but properties are respected.
$data = $mp->unpack($data)
$data = $mp->decode($data)
Same as Data::MessagePack->unpack(), but properties are respected.
Configuration Variables (DEPRECATED)
$Data::MessagePack::PreferInteger
Packs a string as an integer, when it looks like an integer.
This variable is deprecated.
Use $msgpack->prefer_integer property instead.
SPEED
This is a result of benchmark/serialize.pl and benchmark/deserialize.pl
on my SC440(Linux 2.6.32-23-server #37-Ubuntu SMP).
(You should benchmark them with your data if the speed matters, of course.)
This module can unpack 64 bit integers even if your perl does not support them
(i.e. where perl -V:ivsize is 4), but you cannot calculate these values
unless you use Math::BigInt.
TODO
Error handling
MessagePack cannot deal with complex scalars such as object references,
filehandles, and code references. We should report the errors more kindly.
Streaming deserializer
The current implementation of the streaming deserializer does not have internal
buffers while some other bindings (such as Ruby binding) does. This limitation
will astonish those who try to unpack byte streams with an arbitrary buffer size
(e.g. while(read($socket, $buffer, $arbitrary_buffer_size)) { ... }).
We should implement the internal buffer for the unpacker.
FAQ
Why does Data::MessagePack have pure perl implementations?
msgpack C library uses C99 feature, VC++6 does not support C99. So pure perl version is needed for VC++ users.
AUTHORS
Tokuhiro Matsuno
Makamaka Hannyaharamitu
gfx
THANKS TO
Jun Kuriyama
Dan Kogai
FURUHASHI Sadayuki
hanekomu
Kazuho Oku
syohex
LICENSE
This library is free software; you can redistribute it and/or modify
it under the same terms as Perl itself.
Data::MessagePack - Perl 6 implementation of MessagePack
SYNOPSIS
use Data::MessagePack;
my $data-structure = {
key => 'value',
k2 => [ 1, 2, 3 ]
};
my $packed = Data::MessagePack::pack( $data-structure );
my $unpacked = Data::MessagePack::unpack( $packed );
Or for streaming:
use Data::MessagePack::StreamingUnpacker;
my $supplier = Some Supplier; #Could be from IO::Socket::Async for instance
my $unpacker = Data::MessagePack::StreamingUnpacker.new(
source => $supplier.Supply
);
$unpacker.tap( -> $value {
say "Got new value";
say $value.perl;
}, done => { say "Source supply is done"; } );
DESCRIPTION
The present module proposes an implemetation of the MessagePack specification as described on http://msgpack.org/. The implementation is now in Pure Perl which could come as a performance penalty opposed to some other packer implemented in C.
WHY THAT MODULE
There are already some part of MessagePack implemented in Perl6, with for instance MessagePack available here: https://github.com/uasi/messagepack-pm6, however that module only implements the unpacking part of the specification. Futhermore, that module uses the unpack functionality which is tagged as experimental as of today
FUNCTIONS
function pack
That function takes a data structure as parameter, and returns a Blob with the packed version of the data structure.
function unpack
That function takes a MessagePack packed message as parameter, and returns the deserialized data structure.
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
MessagePack is an efficient binary serialization format.
It lets you exchange data among multiple languages like JSON.
But it's faster and smaller.
This package provides CPython bindings for reading and writing MessagePack data.
Very important notes for existing users
PyPI package name
Package name on PyPI was changed from msgpack-python to msgpack from 0.5.
When upgrading from msgpack-0.4 or earlier, do pip uninstall msgpack-python before
pip install -U msgpack.
Compatibility with the old format
You can use use_bin_type=False option to pack bytes
object into raw type in the old msgpack spec, instead of bin type in new msgpack spec.
You can unpack old msgpack format using raw=True option.
It unpacks str (raw) type in msgpack into Python bytes.
See note below for detail.
Major breaking changes in msgpack 1.0
Python 2
The extension module does not support Python 2 anymore.
The pure Python implementation (msgpack.fallback) is used for Python 2.
Packer
use_bin_type=True by default. bytes are encoded in bin type in msgpack.
If you are still using Python 2, you must use unicode for all string types.
You can use use_bin_type=False to encode into old msgpack format.
encoding option is removed. UTF-8 is used always.
Unpacker
raw=False by default. It assumes str types are valid UTF-8 string
and decode them to Python str (unicode) object.
encoding option is removed. You can use raw=True to support old format.
Default value of max_buffer_size is changed from 0 to 100 MiB.
Default value of strict_map_key is changed to True to avoid hashdos.
You need to pass strict_map_key=False if you have data which contain map keys
which type is not bytes or str.
Install
$ pip install msgpack
Pure Python implementation
The extension module in msgpack (msgpack._cmsgpack) does not support
Python 2 and PyPy.
But msgpack provides a pure Python implementation (msgpack.fallback)
for PyPy and Python 2.
Windows
When you can't use a binary distribution, you need to install Visual Studio
or Windows SDK on Windows.
Without extension, using pure Python implementation on CPython runs slowly.
How to use
NOTE: In examples below, I use raw=False and use_bin_type=True for users
using msgpack < 1.0. These options are default from msgpack 1.0 so you can omit them.
One-shot pack & unpack
Use packb for packing and unpackb for unpacking.
msgpack provides dumps and loads as an alias for compatibility with
json and pickle.
pack and dump packs to a file-like object.
unpack and load unpacks from a file-like object.
As an alternative to iteration, Unpacker objects provide unpack,
skip, read_array_header and read_map_header methods. The former two
read an entire message from the stream, respectively de-serialising and returning
the result, or ignoring it. The latter two methods return the number of elements
in the upcoming container, so that each element in an array, or key-value pair
in a map, can be unpacked or skipped individually.
Notes
string and binary type
Early versions of msgpack didn't distinguish string and binary types.
The type for representing both string and binary types was named raw.
You can pack into and unpack from this old spec using use_bin_type=False
and raw=True options.
You can use it with default and ext_hook. See below.
Security
To unpacking data received from unreliable source, msgpack provides
two security options.
max_buffer_size (default: 100*1024*1024) limits the internal buffer size.
It is used to limit the preallocated list size too.
strict_map_key (default: True) limits the type of map keys to bytes and str.
While msgpack spec doesn't limit the types of the map keys,
there is a risk of the hashdos.
If you need to support other types for map keys, use strict_map_key=False.
Performance tips
CPython's GC starts when growing allocated object.
This means unpacking may cause useless GC.
You can use gc.disable() when unpacking large message.
List is the default sequence type of Python.
But tuple is lighter than list.
You can use use_list=False while unpacking when performance is important.
u-msgpack-python is a lightweight MessagePack serializer and deserializer module written in pure Python, compatible with both Python 2 and 3, as well CPython and PyPy implementations of Python. u-msgpack-python is fully compliant with the latest MessagePack specification.
ormsgpack is a fast msgpack library for Python. It is a fork/reboot of orjson
It serializes faster than msgpack-python and deserializes a bit slower (right now).
It supports serialization of:
dataclass,
datetime,
numpy,
pydantic and
UUID instances natively.
Its features and drawbacks compared to other Python msgpack libraries:
serializes dataclass instances natively.
serializes datetime, date, and time instances to RFC 3339 format,
e.g., "1970-01-01T00:00:00+00:00"
serializes numpy.ndarray instances natively and faster.
serializes pydantic.BaseModel instances natively (disregards the configuration ATM).
serializes arbitrary types using a default hook
ormsgpack supports CPython 3.6, 3.7, 3.8, 3.9, and 3.10. ormsgpack does not support PyPy. Releases follow semantic
versioning and serializing a new object type without an opt-in flag is
considered a breaking change.
ormsgpack is licensed under both the Apache 2.0 and MIT licenses. The
repository and issue tracker is
github.com/aviramha/ormsgpack, and patches may be
submitted there. There is a
CHANGELOG
available in the repository.
It natively serializes
bytes, str, dict, list, tuple, int, float, bool,
dataclasses.dataclass, typing.TypedDict, datetime.datetime,
datetime.date, datetime.time, uuid.UUID, numpy.ndarray, and
None instances. It supports arbitrary types through default. It
serializes subclasses of str, int, dict, list,
dataclasses.dataclass, and enum.Enum. It does not serialize subclasses
of tuple to avoid serializing namedtuple objects as arrays. To avoid
serializing subclasses, specify the option ormsgpack.OPT_PASSTHROUGH_SUBCLASS.
The output is a bytes object containing UTF-8.
The global interpreter lock (GIL) is held for the duration of the call.
It raises MsgpackEncodeError on an unsupported type. This exception message
describes the invalid object with the error message
Type is not JSON serializable: .... To fix this, specify
default.
It raises MsgpackEncodeError on a str that contains invalid UTF-8.
It raises MsgpackEncodeError if a dict has a key of a type other than str or bytes,
unless OPT_NON_STR_KEYS is specified.
It raises MsgpackEncodeError if the output of default recurses to handling by
default more than 254 levels deep.
It raises MsgpackEncodeError on circular references.
It raises MsgpackEncodeError if a tzinfo on a datetime object is
unsupported.
MsgpackEncodeError is a subclass of TypeError. This is for compatibility
with the standard library.
default
To serialize a subclass or arbitrary types, specify default as a
callable that returns a supported type. default may be a function,
lambda, or callable class instance. To specify that a type was not
handled by default, raise an exception such as TypeError.
The default callable may return an object that itself
must be handled by default up to 254 times before an exception
is raised.
It is important that default raise an exception if a type cannot be handled.
Python otherwise implicitly returns None, which appears to the caller
like a legitimate value and is serialized:
To modify how data is serialized, specify option. Each option is an integer
constant in ormspgack. To specify multiple options, mask them together, e.g.,
option=ormspgack.OPT_NON_STR_KEYS | ormspgack.OPT_NAIVE_UTC.
OPT_NAIVE_UTC
Serialize datetime.datetime objects without a tzinfo as UTC. This
has no effect on datetime.datetime objects that have tzinfo set.
Serialize dict keys of type other than str. This allows dict keys
to be one of str, int, float, bool, None, datetime.datetime,
datetime.date, datetime.time, enum.Enum, and uuid.UUID. For comparison,
the standard library serializes str, int, float, bool or None by
default.
These types are generally serialized how they would be as
values, e.g., datetime.datetime is still an RFC 3339 string and respects
options affecting it.
This option has the risk of creating duplicate keys. This is because non-str
objects may serialize to the same str as an existing key, e.g.,
{"1970-01-01T00:00:00+00:00": true, datetime.datetime(1970, 1, 1, 0, 0, 0): false}.
The last key to be inserted to the dict will be serialized last and a msgpack deserializer will presumably take the last
occurrence of a key (in the above, false). The first value will be lost.
OPT_OMIT_MICROSECONDS
Do not serialize the microsecond field on datetime.datetime and
datetime.time instances.
Enables passthrough of big (Python) ints. By setting this option, one can set a default function for ints larger than 63 bits, smaller ints are still serialized efficiently.
Passthrough datetime.datetime, datetime.date, and datetime.time instances
to default. This allows serializing datetimes to a custom format, e.g.,
HTTP dates:
unpackb() deserializes msgpack to Python objects. It deserializes to dict,
list, int, float, str, bool, bytes and None objects.
bytes, bytearray, memoryview input are accepted.
ormsgpack maintains a cache of map keys for the duration of the process. This
causes a net reduction in memory usage by avoiding duplicate strings. The
keys must be at most 64 bytes to be cached and 512 entries are stored.
The global interpreter lock (GIL) is held for the duration of the call.
It raises MsgpackDecodeError if given an invalid type or invalid
msgpack.
MsgpackDecodeError is a subclass of ValueError.
option
unpackb() supports the OPT_NON_STR_KEYS option, that is similar to original msgpack's strict_map_keys=False.
Be aware that this option is considered unsafe and disabled by default in msgpack due to possibility of HashDoS.
Types
dataclass
ormsgpack serializes instances of dataclasses.dataclass natively. It serializes
instances 40-50x as fast as other libraries and avoids a severe slowdown seen
in other libraries compared to serializing dict.
It is supported to pass all variants of dataclasses, including dataclasses
using __slots__, frozen dataclasses, those with optional or default
attributes, and subclasses. There is a performance benefit to not
using __slots__.
Dataclasses are serialized as maps, with every attribute serialized and in
the order given on class definition:
Users may wish to control how dataclass instances are serialized, e.g.,
to not serialize an attribute or to change the name of an
attribute when serialized. ormsgpack may implement support using the
metadata mapping on field attributes,
e.g., field(metadata={"json_serialize": False}), if use cases are clear.
Performance
--------------------------------------------------------------------------------- benchmark 'dataclass': 2 tests --------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_dataclass_ormsgpack 3.4248 (1.0) 7.7949 (1.0) 3.6266 (1.0) 0.3293 (1.0) 3.5815 (1.0) 0.0310 (1.0) 4;34 275.7434 (1.0) 240 1
test_dataclass_msgpack 140.2774 (40.96) 143.6087 (18.42) 141.3847 (38.99) 1.0038 (3.05) 141.1823 (39.42) 0.7304 (23.60) 2;1 7.0729 (0.03) 8 1
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
datetime
ormsgpack serializes datetime.datetime objects to
RFC 3339 format,
e.g., "1970-01-01T00:00:00+00:00". This is a subset of ISO 8601 and
compatible with isoformat() in the standard library.
datetime.datetime supports instances with a tzinfo that is None,
datetime.timezone.utc, a timezone instance from the python3.9+ zoneinfo
module, or a timezone instance from the third-party pendulum, pytz, or
dateutil/arrow libraries.
Errors with tzinfo result in MsgpackEncodeError being raised.
It is faster to have ormsgpack serialize datetime objects than to do so
before calling packb(). If using an unsupported type such as
pendulum.datetime, use default.
To disable serialization of datetime objects specify the option
ormsgpack.OPT_PASSTHROUGH_DATETIME.
To use "Z" suffix instead of "+00:00" to indicate UTC ("Zulu") time, use the option
ormsgpack.OPT_UTC_Z.
To assume datetimes without timezone are UTC, se the option ormsgpack.OPT_NAIVE_UTC.
enum
ormsgpack serializes enums natively. Options apply to their values.
ormsgpack serializes and deserializes double precision floats with no loss of
precision and consistent rounding.
int
ormsgpack serializes and deserializes 64-bit integers by default. The range
supported is a signed 64-bit integer's minimum (-9223372036854775807) to
an unsigned 64-bit integer's maximum (18446744073709551615).
numpy
ormsgpack natively serializes numpy.ndarray and individual numpy.float64,
numpy.float32, numpy.int64, numpy.int32, numpy.int8, numpy.uint64,
numpy.uint32, and numpy.uint8 instances. Arrays may have a
dtype of numpy.bool, numpy.float32, numpy.float64, numpy.int32,
numpy.int64, numpy.uint32, numpy.uint64, numpy.uintp, or numpy.intp.
ormsgpack is faster than all compared libraries at serializing
numpy instances. Serializing numpy data requires specifying
option=ormsgpack.OPT_SERIALIZE_NUMPY.
The array must be a contiguous C array (C_CONTIGUOUS) and one of the
supported datatypes.
If an array is not a contiguous C array or contains an supported datatype,
ormsgpack falls through to default. In default, obj.tolist() can be
specified. If an array is malformed, which is not expected,
ormsgpack.MsgpackEncodeError is raised.
Performance
---------------------------------------------------------------------------------- benchmark 'numpy float64': 2 tests ---------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_numpy_ormsgpack[float64] 77.9625 (1.0) 85.2507 (1.0) 79.0326 (1.0) 1.9043 (1.0) 78.5505 (1.0) 0.7408 (1.0) 1;1 12.6530 (1.0) 13 1
test_numpy_msgpack[float64] 511.5176 (6.56) 606.9395 (7.12) 559.0017 (7.07) 44.0661 (23.14) 572.5499 (7.29) 81.2972 (109.75) 3;0 1.7889 (0.14) 5 1
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------- benchmark 'numpy int32': 2 tests -------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_numpy_ormsgpack[int32] 197.8751 (1.0) 210.3111 (1.0) 201.1033 (1.0) 5.1886 (1.0) 198.8518 (1.0) 3.8297 (1.0) 1;1 4.9726 (1.0) 5 1
test_numpy_msgpack[int32] 1,363.8515 (6.89) 1,505.4747 (7.16) 1,428.2127 (7.10) 53.4176 (10.30) 1,425.3516 (7.17) 72.8064 (19.01) 2;0 0.7002 (0.14) 5 1
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------- benchmark 'numpy int8': 2 tests ---------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_numpy_ormsgpack[int8] 107.8013 (1.0) 113.7336 (1.0) 109.0364 (1.0) 1.7805 (1.0) 108.3574 (1.0) 0.4066 (1.0) 1;2 9.1712 (1.0) 10 1
test_numpy_msgpack[int8] 685.4149 (6.36) 703.2958 (6.18) 693.2396 (6.36) 7.9572 (4.47) 691.5435 (6.38) 14.4142 (35.45) 1;0 1.4425 (0.16) 5 1
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------- benchmark 'numpy npbool': 2 tests --------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_numpy_ormsgpack[npbool] 87.9005 (1.0) 89.5460 (1.0) 88.7928 (1.0) 0.5098 (1.0) 88.8508 (1.0) 0.6609 (1.0) 4;0 11.2622 (1.0) 12 1
test_numpy_msgpack[npbool] 1,095.0599 (12.46) 1,176.3442 (13.14) 1,120.5916 (12.62) 32.9993 (64.73) 1,110.4216 (12.50) 38.4189 (58.13) 1;0 0.8924 (0.08) 5 1
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------- benchmark 'numpy uint8': 2 tests ---------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_numpy_ormsgpack[uint8] 133.1743 (1.0) 134.7246 (1.0) 134.2793 (1.0) 0.4946 (1.0) 134.3120 (1.0) 0.4492 (1.0) 1;1 7.4472 (1.0) 8 1
test_numpy_msgpack[uint8] 727.1393 (5.46) 824.8247 (6.12) 775.7032 (5.78) 34.9887 (70.73) 775.9595 (5.78) 36.2824 (80.78) 2;0 1.2892 (0.17) 5 1
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
uuid
ormsgpack serializes uuid.UUID instances to
RFC 4122 format, e.g.,
"f81d4fae-7dec-11d0-a765-00a0c91e6bf6".
ormsgpack serializes pydantic.BaseModel instances natively. Currently it ignores pydantic.BaseModel.Config.
Performance
-------------------------------------------------------------------------------- benchmark 'pydantic': 2 tests ---------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_pydantic_ormsgpack 4.3918 (1.0) 12.6521 (1.0) 4.8550 (1.0) 1.1455 (3.98) 4.6101 (1.0) 0.0662 (1.0) 11;24 205.9727 (1.0) 204 1
test_pydantic_msgpack 124.5500 (28.36) 125.5427 (9.92) 125.0582 (25.76) 0.2877 (1.0) 125.0855 (27.13) 0.2543 (3.84) 2;0 7.9963 (0.04) 8 1
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Latency
Graphs
Data
----------------------------------------------------------------------------- benchmark 'canada packb': 2 tests ------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_ormsgpack_packb[canada] 3.5302 (1.0) 3.8939 (1.0) 3.7319 (1.0) 0.0563 (1.0) 3.7395 (1.0) 0.0484 (1.0) 56;22 267.9571 (1.0) 241 1
test_msgpack_packb[canada] 8.8642 (2.51) 14.0432 (3.61) 9.3660 (2.51) 0.5649 (10.03) 9.2983 (2.49) 0.0982 (2.03) 3;11 106.7691 (0.40) 106 1
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------- benchmark 'canada unpackb': 2 tests --------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_msgpack_unpackb[canada] 10.1176 (1.0) 62.0466 (1.18) 33.4806 (1.0) 18.8279 (1.0) 46.6582 (1.0) 38.5921 (1.02) 30;0 29.8680 (1.0) 67 1
test_ormsgpack_unpackb[canada] 11.3992 (1.13) 52.6587 (1.0) 34.1842 (1.02) 18.9461 (1.01) 47.6456 (1.02) 37.8024 (1.0) 8;0 29.2533 (0.98) 20 1
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------- benchmark 'citm_catalog packb': 2 tests -----------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_ormsgpack_packb[citm_catalog] 1.8024 (1.0) 2.1259 (1.0) 1.9487 (1.0) 0.0346 (1.0) 1.9525 (1.0) 0.0219 (1.0) 79;60 513.1650 (1.0) 454 1
test_msgpack_packb[citm_catalog] 3.4195 (1.90) 3.8128 (1.79) 3.6928 (1.90) 0.0535 (1.55) 3.7009 (1.90) 0.0250 (1.14) 47;49 270.7958 (0.53) 257 1
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------ benchmark 'citm_catalog unpackb': 2 tests ------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_ormsgpack_unpackb[citm_catalog] 5.6986 (1.0) 46.1843 (1.0) 14.2491 (1.0) 15.9791 (1.0) 6.1051 (1.0) 0.3074 (1.0) 5;5 70.1798 (1.0) 23 1
test_msgpack_unpackb[citm_catalog] 7.2600 (1.27) 56.6642 (1.23) 16.4095 (1.15) 16.3257 (1.02) 7.7364 (1.27) 0.4944 (1.61) 28;29 60.9404 (0.87) 125 1
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------- benchmark 'github packb': 2 tests -----------------------------------------------------------------------------------
Name (time in us) Min Max Mean StdDev Median IQR Outliers OPS (Kops/s) Rounds Iterations
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_ormsgpack_packb[github] 73.0000 (1.0) 215.9000 (1.0) 80.4826 (1.0) 4.8889 (1.0) 80.3000 (1.0) 1.1000 (1.83) 866;1118 12.4250 (1.0) 6196 1
test_msgpack_packb[github] 103.8000 (1.42) 220.8000 (1.02) 112.8049 (1.40) 4.9686 (1.02) 113.0000 (1.41) 0.6000 (1.0) 1306;1560 8.8649 (0.71) 7028 1
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------- benchmark 'github unpackb': 2 tests -----------------------------------------------------------------------------------
Name (time in us) Min Max Mean StdDev Median IQR Outliers OPS (Kops/s) Rounds Iterations
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_ormsgpack_unpackb[github] 201.3000 (1.0) 318.5000 (1.0) 219.0861 (1.0) 6.7340 (1.0) 219.1000 (1.0) 1.2000 (1.0) 483;721 4.5644 (1.0) 3488 1
test_msgpack_unpackb[github] 289.8000 (1.44) 436.0000 (1.37) 314.9631 (1.44) 9.4130 (1.40) 315.1000 (1.44) 2.3000 (1.92) 341;557 3.1750 (0.70) 2477 1
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------- benchmark 'twitter packb': 2 tests ---------------------------------------------------------------------------------------
Name (time in us) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_ormsgpack_packb[twitter] 820.7000 (1.0) 2,945.2000 (2.03) 889.3791 (1.0) 78.4139 (2.43) 884.2000 (1.0) 12.5250 (1.0) 4;76 1,124.3799 (1.0) 809 1
test_msgpack_packb[twitter] 1,209.3000 (1.47) 1,451.2000 (1.0) 1,301.3615 (1.46) 32.2147 (1.0) 1,306.7000 (1.48) 14.1000 (1.13) 118;138 768.4260 (0.68) 592 1
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------ benchmark 'twitter unpackb': 2 tests -----------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_ormsgpack_unpackb[twitter] 2.7097 (1.0) 41.1530 (1.0) 3.2721 (1.0) 3.5860 (1.03) 2.8868 (1.0) 0.0614 (1.32) 4;38 305.6098 (1.0) 314 1
test_msgpack_unpackb[twitter] 3.8079 (1.41) 42.0617 (1.02) 4.4459 (1.36) 3.4893 (1.0) 4.1097 (1.42) 0.0465 (1.0) 2;54 224.9267 (0.74) 228 1
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Reproducing
The above was measured using Python 3.7.9 on Azure Linux VM (x86_64) with ormsgpack 0.2.1 and msgpack 1.0.2.
The latency results can be reproduced using ./scripts/benchmark.sh and graphs using
pytest --benchmark-histogram benchmarks/bench_*.
Questions
Why can't I install it from PyPI?
Probably pip needs to be upgraded to version 20.3 or later to support
the latest manylinux_x_y or universal2 wheel formats.
Will it deserialize to dataclasses, UUIDs, decimals, etc or support object_hook?
No. This requires a schema specifying what types are expected and how to
handle errors etc. This is addressed by data validation libraries a
level above this.
Will it support PyPy?
If someone implements it well.
Packaging
To package ormsgpack requires Rust on the
nightly channel and the maturin
build tool. maturin can be installed from PyPI or packaged as
well. This is the simplest and recommended way of installing
from source, assuming rustup is available from a
package manager:
This is an example of building a wheel using the repository as source,
rustup installed from upstream, and a pinned version of Rust:
pip install maturin
curl https://sh.rustup.rs -sSf | sh -s -- --default-toolchain nightly-2021-05-25 --profile minimal -y
export RUSTFLAGS="-C target-cpu=k8"
maturin build --release --strip --manylinux off
ls -1 target/wheels
Problems with the Rust nightly channel may require pinning a version.
nightly-2021-05-25 is known to be ok.
ormsgpack is tested for amd64 and aarch64 on Linux, macOS, and Windows. It
may not work on 32-bit targets. It has recommended RUSTFLAGS
specified in .cargo/config so it is recommended to either not set
RUSTFLAGS or include these options.
There are no runtime dependencies other than libc.
License
orjson was written by ijl <[email protected]>, copyright 2018 - 2021, licensed
under both the Apache 2 and MIT licenses.
ormsgpack was forked from orjson and is maintained by Aviram Hassan <[email protected]>, licensed
same as orjson.
txmsgpackrpc is a library for writing asynchronous
msgpack-rpc
servers and clients in Python, using Twisted
framework. Library is based on
txMsgpack, but some
improvements and fixes were made.
Features
user friendly API
modular object model
working timeouts and reconnecting
connection pool support
TCP, SSL, UDP and UNIX sockets
Python 3 note
To use UNIX sockets with Python 3 please use Twisted framework 15.3.0 and above.
Computation of PI with 5 places finished in 0.022390 seconds
Computation of PI with 100 places finished in 0.037856 seconds
Computation of PI with 1000 places finished in 0.038070 seconds
Computation of PI with 10000 places finished in 0.073907 seconds
Computation of PI with 100000 places finished in 6.741683 seconds
Computation of PI with 5 places finished in 0.001142 seconds
Computation of PI with 100 places finished in 0.001182 seconds
Computation of PI with 1000 places finished in 0.001206 seconds
Computation of PI with 10000 places finished in 0.001230 seconds
Computation of PI with 100000 places finished in 0.001255 seconds
Computation of PI with 1000000 places finished in 432.574457 seconds
Computation of PI with 1000000 places finished in 402.551226 seconds
DONE
Server
from __future__ importprint_functionfromcollectionsimportdefaultdictfromtwisted.internetimportdefer, reactor, utilsfromtwisted.pythonimportfailurefromtxmsgpackrpc.serverimportMsgpackRPCServerpi_chudovsky_bs='''"""Python3 program to calculate Pi using python long integers, binarysplitting and the Chudnovsky algorithmSee: http://www.craig-wood.com/nick/articles/pi-chudnovsky/ for moreinfoNick Craig-Wood <[email protected]>"""import mathfrom time import timedef sqrt(n, one): """ Return the square root of n as a fixed point number with the one passed in. It uses a second order Newton-Raphson convgence. This doubles the number of significant figures on each iteration. """ # Use floating point arithmetic to make an initial guess floating_point_precision = 10**16 n_float = float((n * floating_point_precision) // one) / floating_point_precision x = (int(floating_point_precision * math.sqrt(n_float)) * one) // floating_point_precision n_one = n * one while 1: x_old = x x = (x + n_one // x) // 2 if x == x_old: break return xdef pi_chudnovsky_bs(digits): """ Compute int(pi * 10**digits) This is done using Chudnovsky's series with binary splitting """ C = 640320 C3_OVER_24 = C**3 // 24 def bs(a, b): """ Computes the terms for binary splitting the Chudnovsky infinite series a(a) = +/- (13591409 + 545140134*a) p(a) = (6*a-5)*(2*a-1)*(6*a-1) b(a) = 1 q(a) = a*a*a*C3_OVER_24 returns P(a,b), Q(a,b) and T(a,b) """ if b - a == 1: # Directly compute P(a,a+1), Q(a,a+1) and T(a,a+1) if a == 0: Pab = Qab = 1 else: Pab = (6*a-5)*(2*a-1)*(6*a-1) Qab = a*a*a*C3_OVER_24 Tab = Pab * (13591409 + 545140134*a) # a(a) * p(a) if a & 1: Tab = -Tab else: # Recursively compute P(a,b), Q(a,b) and T(a,b) # m is the midpoint of a and b m = (a + b) // 2 # Recursively calculate P(a,m), Q(a,m) and T(a,m) Pam, Qam, Tam = bs(a, m) # Recursively calculate P(m,b), Q(m,b) and T(m,b) Pmb, Qmb, Tmb = bs(m, b) # Now combine Pab = Pam * Pmb Qab = Qam * Qmb Tab = Qmb * Tam + Pam * Tmb return Pab, Qab, Tab # how many terms to compute DIGITS_PER_TERM = math.log10(C3_OVER_24/6/2/6) N = int(digits/DIGITS_PER_TERM + 1) # Calclate P(0,N) and Q(0,N) P, Q, T = bs(0, N) one = 10**digits sqrtC = sqrt(10005*one, one) return (Q*426880*sqrtC) // Tif __name__ == "__main__": import sys digits = int(sys.argv[1]) pi = pi_chudnovsky_bs(digits) print(pi)'''defset_timeout(deferred, timeout=30):
defcallback(value):
ifnotwatchdog.called:
watchdog.cancel()
returnvaluedeferred.addBoth(callback)
watchdog=reactor.callLater(timeout, defer.timeout, deferred)
classComputePI(MsgpackRPCServer):
def__init__(self):
self.waiting=defaultdict(list)
self.results= {}
defremote_PI(self, digits, timeout=None):
ifdigitsinself.results:
returndefer.succeed(self.results[digits])
d=defer.Deferred()
ifdigitsnotinself.waiting:
subprocessDeferred=self.computePI(digits, timeout)
defcallWaiting(res):
waiting=self.waiting[digits]
delself.waiting[digits]
ifisinstance(res, failure.Failure):
func=lambdad: d.errback(res)
else:
func=lambdad: d.callback(res)
fordinwaiting:
func(d)
subprocessDeferred.addBoth(callWaiting)
self.waiting[digits].append(d)
returnddefcomputePI(self, digits, timeout):
d=utils.getProcessOutputAndValue('/usr/bin/python', args=('-c', pi_chudovsky_bs, str(digits)))
defcallback((out, err, code)):
ifcode==0:
pi=int(out)
self.results[digits] =pireturnpielse:
returnfailure.Failure(RuntimeError('Computation failed: '+err))
iftimeoutisnotNone:
set_timeout(d, timeout)
d.addCallback(callback)
returnddefmain():
server=ComputePI()
reactor.listenTCP(8000, server.getStreamFactory())
if__name__=='__main__':
reactor.callWhenRunning(main)
reactor.run()
Client
from __future__ importprint_functionimportsysimporttimefromtwisted.internetimportdefer, reactor, taskfromtwisted.pythonimportfailure@defer.inlineCallbacksdefmain():
try:
fromtxmsgpackrpc.clientimportconnectc=yieldconnect('localhost', 8000, waitTimeout=900)
defcallback(res, digits, start_time):
ifisinstance(res, failure.Failure):
print('Computation of PI with %d places failed: %s'%
(digits, res.getErrorMessage()), end='\n\n')
else:
print('Computation of PI with %d places finished in %f seconds'%
(digits, time.time() -start_time), end='\n\n')
sys.stdout.flush()
defers= []
for_inrange(2):
fordigitsin (5, 100, 1000, 10000, 100000, 1000000):
d=c.createRequest('PI', digits, 600)
d.addBoth(callback, digits, time.time())
defers.append(d)
# wait for 30 secondsyieldtask.deferLater(reactor, 30, lambda: None)
yielddefer.DeferredList(defers)
print('DONE')
exceptException:
importtracebacktraceback.print_exc()
finally:
reactor.stop()
if__name__=='__main__':
reactor.callWhenRunning(main)
reactor.run()
Multicast UDP example
Example servers join to group 224.0.0.5 and listen on port 8000. Their only
method echo returns its parameter.
Client joins group to 224.0.0.5, sends multicast request to group on port 8000
and waits for 5 seconds for responses. If some responses are received,
protocol callbacks with tuple of results and individual parts are checked for
errors. If no responses are received, protocol errbacks with TimeoutError.
Because there is no common way to determine number of peers in group,
MsgpackMulticastDatagramProtocol always wait for responses until waitTimeout
expires.
// packing
MsgPackStream stream(&ba, QIODevice::WriteOnly);
stream << 1 << 2.3 << "some string";
// unpacking
MsgPackStream stream(ba);
int a;
double b;
QSting s;
stream >> a >> b >> s;
Qt types and User types
There is packers and unpackers for QColor, QTime, QDate, QDateTime, QPoint, QSize, QRect. Also you can create your own packer/unpacker methods for Qt or your own types. See docs for details.
Convert to and from msgpack objects in R using the official msgpack-c API through Rcpp.
A flowchart describing the conversion of R objects into msgpack objects and back.
Msgpack EXT types are converted to raw vectors with EXT attributes containing the extension type. The extension type must be an integer from 0 to 127.
Maps are converted to data.frames with additional class "map". Map objects in R contain key and value list columns and can be simplified to named lists or named vectors. The helper function msgpack_map creates map objects that can be serialized into msgpack.
RMP is designed to be lightweight and straightforward. There are low-level API, which gives you
full control on data encoding/decoding process and makes no heap allocations. On the other hand
there are high-level API, which provides you convenient interface using Rust standard library and
compiler reflection, allowing to encode/decode structures using derive attribute.
Zero-copy value decoding
RMP allows to decode bytes from a buffer in a zero-copy manner easily and blazingly fast, while Rust
static checks guarantees that the data will be valid as long as the buffer lives.
Clear error handling
RMP's error system guarantees that you never receive an error enum with unreachable variant.
Robust and tested
This project is developed using TDD and CI, so any found bugs will be fixed without breaking
existing functionality.
Here is a list of sbt commands for daily development:
> ~compile # Compile source codes
> ~test:compile # Compile both source and test codes
> ~test # Run tests upon source code change
> ~test-only *MessagePackTest # Run tests in the specified class
> ~test-only *MessagePackTest -- -n prim # Run the test tagged as "prim"
> project msgpack-scala # Focus on a specific project
> package # Create a jar file in the target folder of each project
> scalafmt # Reformat source codes
> ; coverage; test; coverageReport; coverageAggregate; # Code coverage
Publishing
> publishLocal # Install to local .ivy2 repository
> publish # Publishing a snapshot version to the Sonatype repository
> release # Run the release procedure (set a new version, run tests, upload artifacts, then deploy to Sonatype)
For publishing to Maven central, msgpack-scala uses sbt-sonatype plugin. Set Sonatype account information (user name and password) in the global sbt settings. To protect your password, never include this file in your project.
msgpack-cli is command line tool that converts data from JSON to Msgpack and vice versa. Also allows calling RPC methods via msgpack-rpc.
Installation
% go get github.com/jakm/msgpack-cli
Debian packages and Windows binaries are available on project's
Releases page.
Usage
msgpack-cli
Usage:
msgpack-cli encode <input-file> [--out=<output-file>] [--disable-int64-conv]
msgpack-cli decode <input-file> [--out=<output-file>] [--pp]
msgpack-cli rpc <host> <port> <method> [<params>|--file=<input-file>] [--pp]
[--timeout=<timeout>][--disable-int64-conv]
msgpack-cli -h | --help
msgpack-cli --version
Commands:
encode Encode data from input file to STDOUT
decode Decode data from input file to STDOUT
rpc Call RPC method and write result to STDOUT
Options:
-h --help Show this help message and exit
--version Show version
--out=<output-file> Write output data to file instead of STDOUT
--file=<input-file> File where parameters or RPC method are read from
--pp Pretty-print - indent output JSON data
--timeout=<timeout> Timeout of RPC call [default: 30]
--disable-int64-conv Disable the default behaviour such that JSON numbers
are converted to float64 or int64 numbers by their
meaning, all result numbers will have float64 type
Arguments:
<input-file> File where data are read from
<host> Server hostname
<port> Server port
<method> Name of RPC method
<params> Parameters of RPC method in JSON format
YSMessagePack is a messagePack packer/unpacker written in swift (swift 3 ready). It is designed to be easy to use. YSMessagePack include following features:
Pack custom structs and classes / unpack objects by groups and apply handler to each group (easier to re-construct your struct$)
Asynchronous unpacking
Pack and unpack multiple message-packed data regardless of types with only one line of code
Specify how many items to unpack
Get remaining bytes that were not message-packed ; start packing from some index -- so you can mix messagepack with other protocol!!!
Helper methods to cast NSData to desired types
Operator +^ and +^= to join NSData
Version
1.6.2 (Dropped swift 2 support, swift 3 support only from now on)
Installation
Simply add files under YSMessagePack/Classes to your project,
use cocoapod, add "pod 'YSMessagePack', '~> 1.6.2' to your podfile
Usage
Pack:
let exampleInt: Int=1let exampleStr: String="Hello World"let exampleArray: [Int] = [1, 2, 3, 4, 5, 6]
let bool: Bool=true// To pack items, just put all of them in a single array// and call the `pack(items:)` function//this will be the packed datalet msgPackedBytes: NSData =pack(items: [true, foo, exampleInt, exampleStr, exampleArray])
// Now your payload is ready to send!!!
But what if we have some custom data structure to send?
//To make your struct / class packablestructMyStruct: Packable { //Confirm to this protocolvar name: Stringvar index: IntfuncpackFormat() -> [Packable] { //protocol functionreturn [name, index] //pack order
}
funcmsgtype() -> MsgPackTypes {
return .Custom
}
}
let exampleInt: Int=1let exampleStr: String="Hello World"let exampleArray: [Int] = [1, 2, 3, 4, 5]
let bool: Bool=truelet foo =MyStruct(name: "foo", index: 626)
let msgPackedBytes =pack(items: [bool, foo, exampleInt, exampleStr, exampleArray])
Or you can pack them individually and add them to a byte array manually (Which is also less expensive)
let exampleInt: Int=1let exampleStr: String="Hello World"let exampleArray: [Int] = [1, 2, 3, 4, 5, 6]
//Now pack them individuallylet packedInt = exampleInt.packed()
//if you didn't specific encoding, the default encoding will be ASCII
#ifswift(>=3)
let packedStr = exampleStr.packed(withEncoding: NSASCIIStringEncoding)
#elselet packedStr = exampleStr.packed(withEncoding: .ascii)
#endiflet packedArray = exampleArray.packed()
//You can use this operator +^ the join the data on rhs to the end of data on lhslet msgPackedBytes: NSData = packedInt +^ packedStr +^ packedArray
Unpack
YSMessagePack offer a number of different ways and options to unpack include unpack asynchronously, see the example project for detail.
To unpack a messagepacked bytearray is pretty easy:
do {
//The unpack method will return an array of NSData which each element is an unpacked objectlet unpackedItems =try msgPackedBytes.itemsUnpacked()
//instead of casting the NSData to the type you want, you can call these `.castTo..` methods to do the job for youlet int: Int= unpackedItems[2].castToInt()
//Same as packing, you can also specify the encoding you want to use, default is ASCIIlet str: String= unpackedItem[3].castToString()
let array: NSArray = unpackedItems[4].castToArray()
} catchlet error as NSError{
NSLog("Error occurs during unpacking: %@", error)
}
//Remember how to pack your struct? Here is a better way to unpack a stream of bytes formatted in specific formatlet testObj1 =MyStruct(name: "TestObject1", index: 1)
let testObj2 =MyStruct(name: "TestObject2", index: 2)
let testObj3 =MyStruct(name: "TestObject3", index: 3)
let packed =packCustomObjects(testObj1, testObj2, testObj3) //This is an other method that can pack your own struct easierlet nobjsInOneGroup =2try! packed.unpackByGroupsWith(nobjsInOneGroup) {
(unpackedData, isLast) ->Bool//you can also involve additional args like number of groups to unpackguardlet name = unpackedData[0].castToString() else {returnfalse} //abort unpacking hen something wronglet index = unpackedData[1]
let testObj =MyStruct(name: name, index: index) // assembly returntrue//proceed unpacking, or return false to abort
}
If you don't want to unpack every single thing included in the message-pack byte array, you can also specify an amount to unpack, if you want to keep the remaining bytes, you can put true in the returnRemainingBytes argument, the remaining bytes will stored in the end of the NSData array.
do {
//Unpack only 2 objects, and we are not interested in remaining byteslet unpackedItems =try msgPackedBytes.itemsUnpacked(specific_amount: 2, returnRemainingBytes: false)
print(unpackedItems.count) //will print 2
} catchlet error as NSError{
NSLog("Error occurs during unpacking: %@", error)
}
MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON. But it's faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves.
let hey =MessagePack("hey there!")
let bytes =try MessagePack.encode(hey)
let original =String(try MessagePack.decode(bytes: bytes))
Stream API
let hey =MessagePack("hey there!")
let stream =BufferedStream(stream: NetworkStream(socket: client))
try MessagePack.encode(hey, to: stream)
try stream.flush()
let original =String(try MessagePack.decode(from: stream))
Performance optimized
let output =OutputByteStream()
var encoder =MessagePackWriter(output)
try encoder.encode("one")
try encoder.encode(2)
try encoder.encode(3.0)
let encoded = output.bytesvar decoder =MessagePackReader(InputByteStream(encoded))
let string =try decoder.decode(String.self)
let int =try decoder.decode(UInt8.self)
let double =try decoder.decode(Double.self)
print("decoded manually: \(string), \(int), \(double)")
msgpack-tools contains simple command-line utilities for converting from MessagePack to JSON and vice-versa. They support options for lax parsing, lossy conversions, pretty-printing, and base64 encoding.
msgpack2json -- Convert MessagePack to JSON
json2msgpack -- Convert JSON to MessagePack
They can be used for dumping MessagePack from a file or web API to a human-readable format, or for converting hand-written or generated JSON to MessagePack. The lax parsing mode supports comments and trailing commas in JSON, making it possible to hand-write your app or game data in JSON and convert it at build-time to MessagePack.
Mac OS X (Homebrew): brew install https://ludocode.github.io/msgpack-tools.rb
Debian (Ubuntu, etc.): .deb package for x86_64 in the latest release; install with dpkg
For other platforms, msgpack-tools must be built from source. Download the msgpack-tools tarball from the latest release page (not the "source code" archive generated by GitHub, but the actual release package.)
msgpack-tools uses CMake. A configure wrapper is provided that calls CMake, so you can simply run the usual:
./configure && make && sudo make install
If you are building from the repository, you will need md2man to generate the man pages.
Differences between MessagePack and JSON
MessagePack is intended to be very close to JSON in supported features, so they can usually be transparently converted from one to the other. There are some differences, however, which can complicate conversions.
These are the differences in what objects are representable in each format:
JSON keys must be strings. MessagePack keys can be any type, including maps and arrays.
JSON supports "bignums", i.e. integers of any size. MessagePack integers must fit within a 64-bit signed or unsigned integer.
JSON real numbers are specified in decimal scientific notation and can have arbitrary precision. MessagePack real numbers are in IEEE 754 standard 32-bit or 64-bit binary.
MessagePack supports binary and extension type objects. JSON does not support binary data. Binary data is often encoded into a base64 string to be embedded into a JSON document.
A JSON document can be encoded in UTF-8, UTF-16 or UTF-32, and the entire document must be in the same encoding. MessagePack strings are required to be UTF-8, although this is not enforced by many encoding/decoding libraries.
By default, msgpack2json and json2msgpack convert in strict mode. If an object in the source format is not representable in the destination format, the converter aborts with an error. A lax mode is available which performs a "lossy" conversion, and base64 conversion modes are available to support binary data in JSON.
NOTE:
Timestamp support is available in core library as well, the additional library just adds a specific serializer that can be used with kotlinx-datetime types. These are MsgPackTimestamp32DatetimeSerializer, MsgPackTimestamp64DatetimeSerializer and MsgPackTimestamp96DatetimeSerializer.
For experimental kotlin unsigned types support, use serialization-msgpack-unsigned-support:
Library should be used in same way as any other kotlinx.serialization library. Created models are annotated with @Serializable annotation and their serializer() can be passed to MsgPack.
mruby-simplemsgpack searches for msgpack-c on your system, if it can find it it links against it, otherwise it builds against msgpack-c from source.
You need at least msgpack-c 1 and depending on your system also pkg-config.
When using MessagePack.unpack with a block and passing it a incomplete packed Message
it returns the position of the first offending byte, if it was able to unpack the whole Message it returns self.
This is helpful if the given data contains an incomplete
last object and we want to continue unpacking after we have more data.
To customize how objects are packed, define an extension type.
By default, MessagePack packs symbols as strings and does not convert them
back when unpacking them. Symbols can be preserved by registering an extension
type for them:
For nil, true, false, Integer, Float, String, Array and Hash a registered
ext type is ignored. They are always packed according to the MessagePack
specification.
Proc, blocks or lambas
If you want to pack and unpack mruby blocks take a look at the mruby-proc-irep-ext gem, it can be registered like the other extension types
Overriding to_msgpack
It's not supported to override to_msgpack, MessagePack.pack ignores it, same when that object is included in a Hash or Array.
This gem treats objects like ruby does, if you want to change the way your custom Class gets handled you can add to_hash, to_ary, to_int or to_str methods so it will be packed like a Hash, Array, Integer or String (in that order) then.
This is a command line tool to inspect/show a data serialized by MessagePack.
Installation
Executable binary files are available from releases. Download a file for your platform, and use it.
Otherwise, you can install rubygem version on your CRuby runtime:
$ gem install msgpack-inspect
Usage
Usage: msgpack-inspect [options] FILE
Options:
-f, --format FORMAT output format of inspection result (yaml/json/jsonl) [default: yaml]
-r, --require LIB ruby file path to require (to load ext type definitions)
-v, --version Show version of this software
-h, --help Show this message
-r option is available oly with rubygem version, and unavailable with mruby binary release.
FILE is a file which msgpack binary stored. Specify - to inspect data from STDIN.
This command shows the all data contained in specified format (YAML in default).
















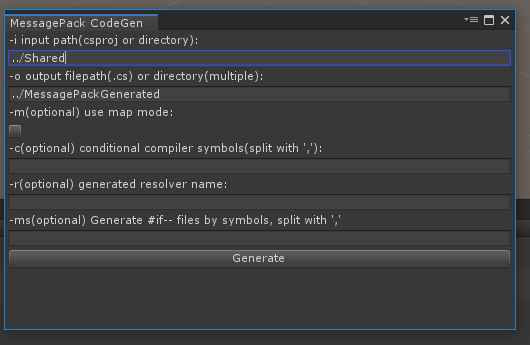




































")
")




















































